Self-Damaging Contrastive Learning Explained!
TL;DR
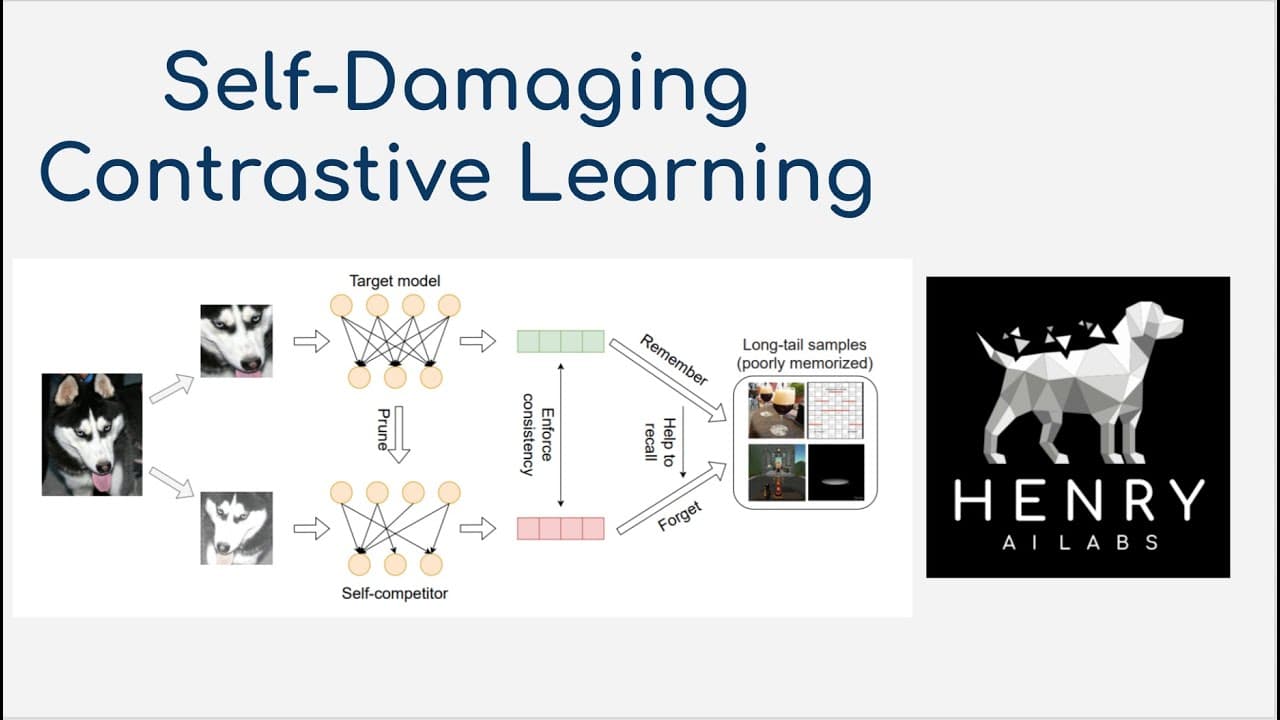
This content explores how self-damaging contrastive learning enhances model accuracy in class-imbalanced datasets through pruning.
Transcript
this video will explain self-damaging contrastive learning this paper is building off of a very exciting paper titled what do compressed deep neural networks forget we've seen the success of pruning where we take a dense neural network and prune away some of the weight set them to zero and somehow it retains the same accuracy basically it'll drop o... Read More
Key Insights
- 🛟 Pruning can reduce network complexity while still preserving accuracy, but it can negatively affect performance on specific data distributions.
- 🏛️ Class imbalance is a prevalent issue in machine learning, impacting the effectiveness of both supervised and unsupervised learning models.
- 🤳 Self-damaging contrastive learning enhances the ability of models to adapt to and learn from infrequent instances by using pruning in training.
- 🖐️ Soft and hard negative mining strategies play a crucial role in improving model robustness against class imbalance.
- 🫥 Evaluating model performance solely based on top-line accuracy may mask crucial weaknesses in the representation of rare class examples.
- 🌍 The proposed learning framework shows potential for practical applications in domains where data imbalance is common, such as real-world image recognition tasks.
- 🏋️ The algorithm encourages deeper exploration of the relationship between model weight architecture and effective representation of data features, particularly in large, unbalanced datasets.
Install to Summarize YouTube Videos and Get Transcripts
Explore YouTube Video Summarizer or Get YouTube Transcript Extractor
Questions & Answers
Q: What is the main focus of self-damaging contrastive learning?
Self-damaging contrastive learning aims to improve model accuracy on data with imbalanced classes by using pruning techniques. It explores how reducing network weights affects performance, especially regarding the long tail of infrequently occurring instances in datasets, enhancing the model's ability to accurately classify these examples.
Q: How does pruning impact model performance during training?
Pruning leads to a reduction in the number of weights in a neural network, which can maintain overall performance but may obscure critical performance details. Specifically, pruned models are more sensitive to changes in data distribution, resulting in potentially decreased accuracy on long-tailed and rare instances, which necessitates careful studies of the effects of various pruning strategies.
Q: What issues arise with using traditional accuracy metrics in imbalanced datasets?
Traditional accuracy metrics can be misleading in imbalanced datasets, as they may not reflect a model's performance on minority classes. In the context discussed, a small drop in top-line accuracy can hide more significant degradation in the ability to correctly classify rarer examples, necessitating more detailed evaluation metrics.
Q: How does self-damaging contrastive learning relate to previous research?
This method builds on the findings of the paper "What Do Compressed Deep Neural Networks Forget?" by leveraging insights on how compression affects representation of infrequent instances. It introduces a framework that optimizes learning through hard negative mining to better capture and represent the long tail of less frequent examples in datasets.
Q: How does self-damaging contrastive learning perform against other methods?
Empirical results show that self-damaging contrastive learning outperforms traditional methods like SimCLR in scenarios involving long-tailed distributions. It effectively improves model representation by focusing on hard-to-classify instances, making it a powerful approach for managing class imbalance in self-supervised learning settings.
Q: What implications does model brittleness have for practical applications?
The brittleness exhibited by compressed model architectures suggests caution in real-world applications where data distributions may shift or differ from the training set. This sensitivity can lead to inaccuracies in predictions, especially for rare classes, underscoring the importance of robust training mechanisms like self-damaging contrastive learning.
Summary & Key Takeaways
-
The concept of self-damaging contrastive learning builds on insights from a prior study, analyzing how pruning affects neural networks' accuracy on rare data instances.
-
Compressed models exhibit increased brittleness to distribution shifts, especially for less frequent examples, leading to performance degradation on long-tailed datasets.
-
The proposed method shows improvements over traditional contrastive learning techniques, particularly in developing robust models for class-imbalanced and sparsely represented data.
Read in Other Languages (beta)
Share This Summary 📚
Summarize YouTube Videos and Get Video Transcripts with 1-Click
Try YouTube Summary with ChatGPT & Claude or YouTube Transcript Generator
Explore More Summaries from Connor Shorten 📚

Summarize YouTube Videos and Get Video Transcripts with 1-Click
Try YouTube Summary with ChatGPT & Claude or YouTube Transcript Generator