Recurrent Neural Networks (RNNs), Clearly Explained!!!
TL;DR
This StatQuest explains recurrent neural networks, their importance in handling varying amounts of sequential data, and the challenges of the Vanishing/Exploding Gradient Problem.
Transcript
Hello, I'm Josh Starmer and welcome to StatQuest. Today we're going to talk about recurrent neural networks, and they're going to be clearly explained! Lightning and Grid are totally cool. Check them out when you've got some time. NOTE: This StatQuest assumes that you are already familiar with the main ideas behind neural networks, backpropagation ... Read More
Key Insights
- 📊 Recurrent neural networks (RNNs) can be used to predict stock prices, but they need to be flexible in terms of the amount of sequential data used for prediction.
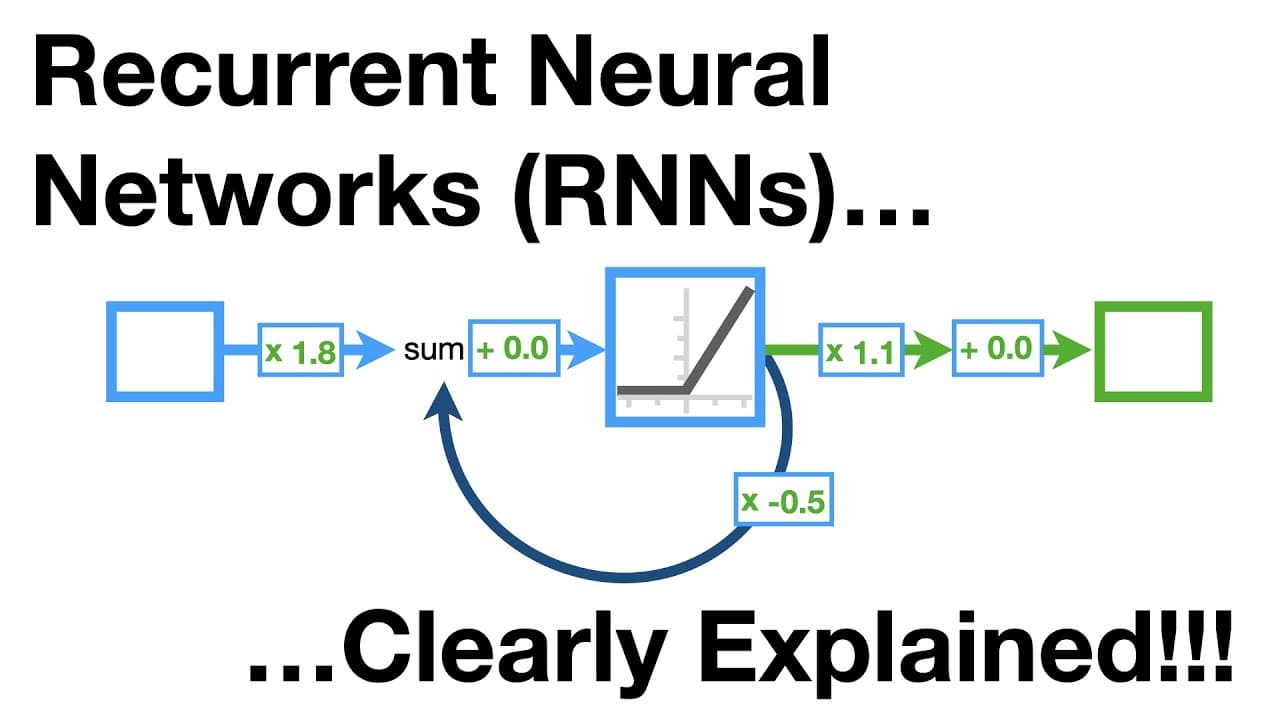
- 💡 RNNs have weights, biases, layers, and activation functions like other neural networks, but they also have feedback loops that allow them to use sequential input values.
- 🔄 Unrolling the feedback loop in an RNN allows us to see the network as a series of copies, with each copy taking inputs from a previous time step and making predictions for the next time step.
- 📈 RNNs can successfully predict stock prices in StatLand by considering the trends in stock prices over multiple days and using scaled input values.
- 🔄 As we unroll an RNN and add more time steps, the network becomes harder to train due to the Vanishing/Exploding Gradient Problem.
- 🔒 The Vanishing/Exploding Gradient Problem occurs when the gradients in the network become too large or too small, making it difficult to find optimal weight and bias values.
- ✅ One solution to the Vanishing/Exploding Gradient Problem is to use Long Short-Term Memory Networks, which will be discussed in a future StatQuest.
Install to Summarize YouTube Videos and Get Transcripts
Explore YouTube Video Summarizer or Get YouTube Transcript Extractor
Questions & Answers
Q: How does a recurrent neural network handle varying amounts of sequential data?
A recurrent neural network uses feedback loops to incorporate previous inputs and make predictions about future data. By unrolling the network, each input becomes part of its own separate network, allowing for flexibility in the length of sequential data.
Q: What are the challenges posed by the Vanishing/Exploding Gradient Problem in recurrent neural networks?
The Vanishing/Exploding Gradient Problem refers to the issue of gradients becoming either too large or too small during training. If the gradients explode, it can result in difficulty in finding optimal weights and biases, whereas if the gradients vanish, it leads to slow optimization and hitting the maximum number of steps before finding the optimal value.
Q: What is the solution to address the Vanishing/Exploding Gradient Problem in recurrent neural networks?
The next StatQuest video will cover Long Short-Term Memory (LSTM) networks, which are a popular solution to the Vanishing/Exploding Gradient Problem in recurrent neural networks. LSTM networks use memory cells and gate mechanisms to retain important information over long sequences and prevent the vanishing/exploding gradient issue.
Q: How does the performance of a recurrent neural network change as the amount of sequential data increases?
As the amount of sequential data increases, the unrolled recurrent neural network also increases in size. This can make training more difficult, as it requires optimizing a larger number of weights and biases, but it also allows for more context and potentially improved predictions.
Summary & Key Takeaways
-
Recurrent neural networks (RNNs) are a type of neural network that can handle varying amounts of sequential data.
-
RNNs include feedback loops, allowing them to use previous inputs to make predictions about future data.
-
The Vanishing/Exploding Gradient Problem can arise in RNNs, making it difficult to train the network effectively.
Read in Other Languages (beta)
Share This Summary 📚
Summarize YouTube Videos and Get Video Transcripts with 1-Click
Try YouTube Summary with ChatGPT & Claude or YouTube Transcript Generator
Explore More Summaries from StatQuest with Josh Starmer 📚




Summarize YouTube Videos and Get Video Transcripts with 1-Click
Try YouTube Summary with ChatGPT & Claude or YouTube Transcript Generator