Lecture 2 | Machine Learning (Stanford) | Summary and Q&A
Summary
In this video, the speaker covers linear regression, gradient descent, and the normal equations. They also introduce the concept of supervised learning and use an example of predicting housing prices to explain linear regression. The speaker showcases the use of gradient descent and demonstrates how it can update the parameters of the hypothesis function to minimize the error between the predicted and actual prices. They then introduce batch gradient descent for larger training sets and discuss how it may not converge exactly but will still find a good solution.
Questions & Answers
Q: What is supervised learning?
Supervised learning is a machine learning problem where the algorithm is provided with labeled examples and is tasked with learning the underlying relationship between the inputs and outputs. In the case of predicting housing prices, the algorithm is given the sizes of houses as inputs and the corresponding correct prices as outputs.
Q: What is the hypothesis function in the context of linear regression?
The hypothesis function, denoted as h(x), is the function that the learning algorithm outputs. In linear regression, it takes the form h(x) = theta0 + theta1*x, where x represents the input feature, in this case, the size of the house. The parameters theta0 and theta1 are learned by the algorithm to best fit the training data and predict the output accurately.
Q: What is the goal of the learning algorithm in linear regression?
The goal is to minimize the difference between the predicted prices and the actual prices in the training set. This is done by updating the parameters theta0 and theta1 of the hypothesis function based on the errors or discrepancies between the predicted and actual prices.
Q: What is gradient descent?
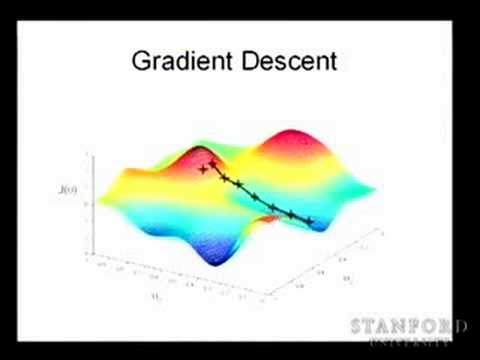
Gradient descent is an optimization algorithm used to find the optimal values for the parameters of a model by iteratively updating them in the direction of steepest descent of a cost function. In the context of linear regression, it calculates the derivative of the cost function with respect to each parameter and updates the parameters accordingly to minimize the error between the predicted and actual prices.
Q: Why is the learning rate alpha important in gradient descent?
The learning rate alpha determines the step size in each iteration of gradient descent. If the learning rate is too large, the algorithm may overshoot the optimal values, potentially oscillating or failing to converge. If the learning rate is too small, the algorithm may take a long time to converge. It is important to choose an appropriate learning rate to ensure convergence to the minimum of the cost function.
Q: What is batch gradient descent?
Batch gradient descent is a variation of gradient descent where the parameters are updated based on the average of the gradients computed over the entire training set. In each iteration, the algorithm calculates the gradients for all training examples and updates the parameters accordingly. It is called "batch" because it uses all training examples simultaneously.
Q: When is stochastic gradient descent used?
Stochastic gradient descent is used when the training set is very large. Instead of using all training examples to compute the gradients, stochastic gradient descent randomly samples one training example in each iteration to calculate the gradient and update the parameters. It is more computationally efficient but may have a more fluctuating convergence path compared to batch gradient descent.
Q: How does the algorithm decide when to stop iterating?
Convergence in gradient descent is typically determined by monitoring the change in the cost function or the parameters over iterations. If the change falls below a certain threshold or the cost function reaches a plateau, the algorithm is often considered to have converged. However, the convergence criteria can vary depending on the specific problem and requirements.
Q: Can gradient descent find the global minimum of the cost function?
In the case of linear regression with ordinary least squares, the cost function is quadratic and has only one global minimum. Therefore, gradient descent can find the global minimum for this problem. However, in other cases, the cost function may have multiple local minima, and gradient descent might get stuck in a suboptimal solution depending on the initialization of the parameters.
Q: What is the closed form solution for linear regression?
The closed form solution for linear regression refers to solving for the optimal parameters theta directly, without the need for an iterative optimization algorithm such as gradient descent. It relies on the normal equations, which are derived by setting the gradients of the cost function with respect to the parameters to zero. The closed form solution allows for a direct calculation of the parameters and can be more computationally efficient for small datasets.