ratl.ai - AI Agents for Autonomous Testing & Software Delivery
studio.ratl.ai/v2/landing/dashboard
Mar 12, 2025
1

3Blue1Brown - Linear transformations and matrices
www.3blue1brown.com/lessons/linear-transformations
Feb 5, 2025
10

3Blue1Brown - Linear combinations, span, and basis vectors
www.3blue1brown.com/lessons/span
Feb 4, 2025
2
Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model
qwenlm.github.io/blog/qwen2.5-max/
Jan 31, 2025
1

Zep Is The New State of the Art In Agent Memory
blog.getzep.com/state-of-the-art-agent-memory/
Jan 23, 2025
4

RAG techniques: From naive to advanced
wandb.ai/site/articles/rag-techniques/
Jan 3, 2025
21

The New Software GTM Playbook by @ttunguz
tomtunguz.com/software-playbook/
Nov 8, 2024
3
A Challenge to SaaS Orthodoxy by @ttunguz
tomtunguz.com/klarna-ai/
Nov 8, 2024
1
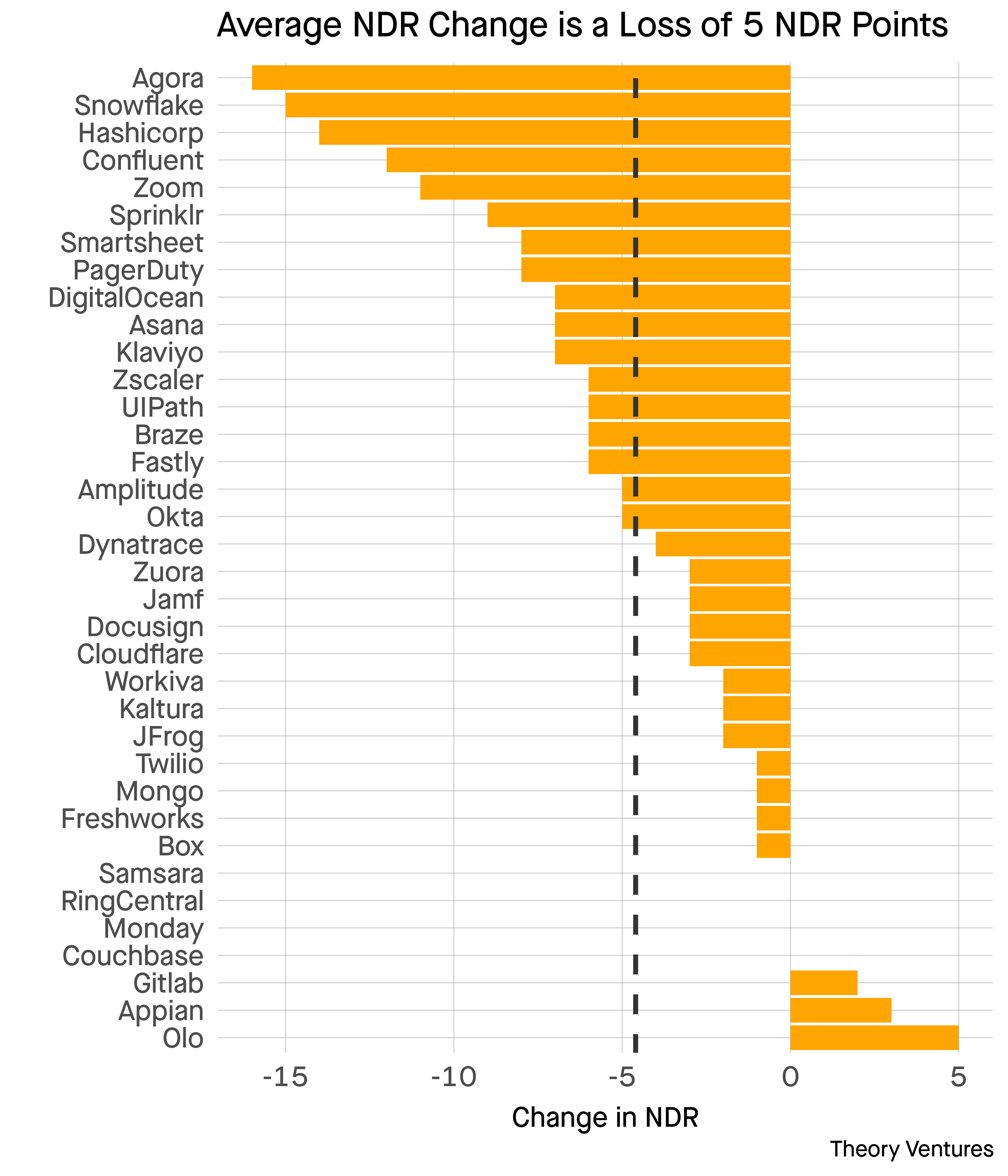
Why Lifetime Value is Relevant Again in Software by @ttunguz
tomtunguz.com/why-ltv-matters-more-in-2024/
Nov 8, 2024
1
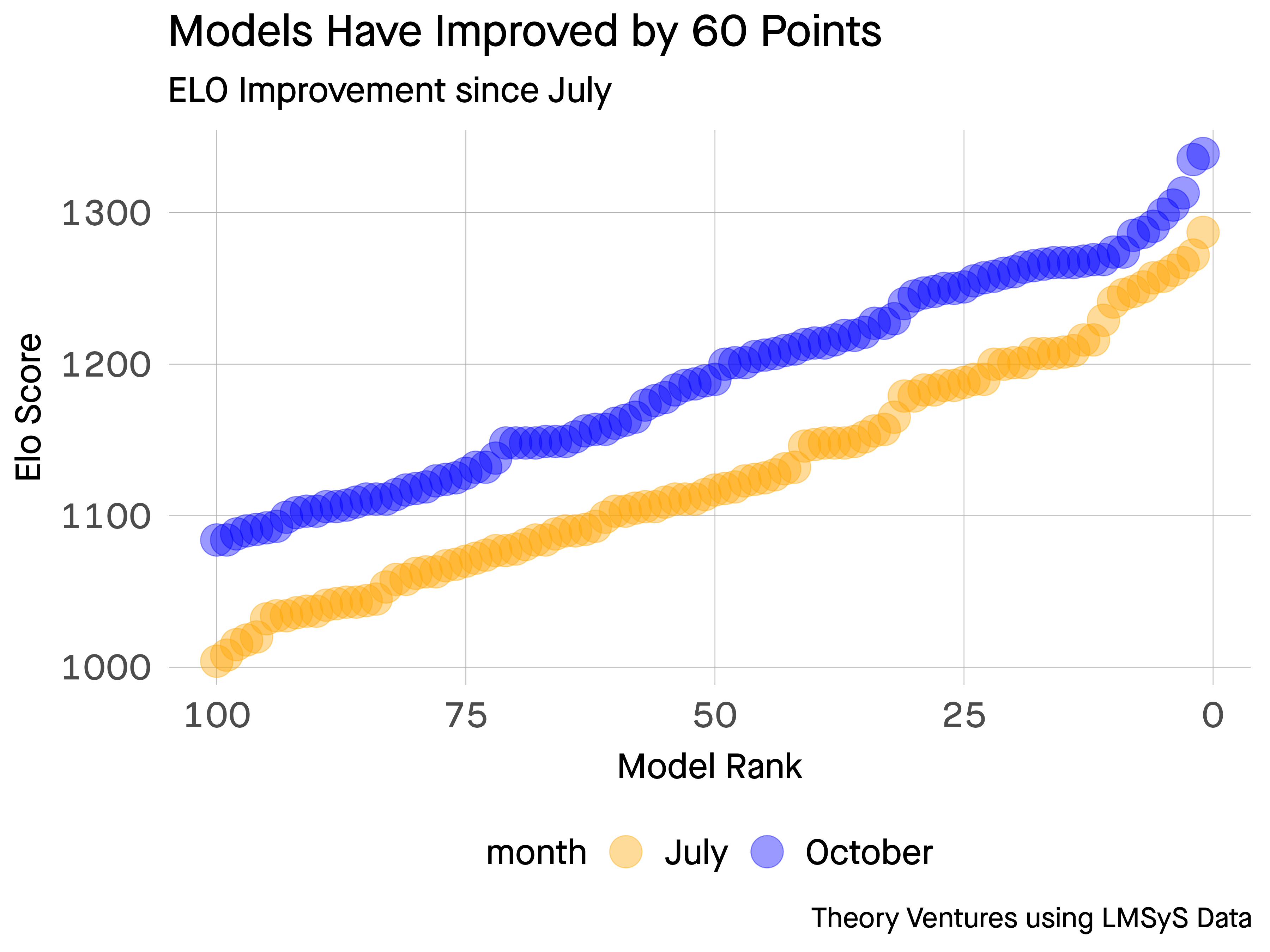
The Premise of a New S-Curve in AI by @ttunguz
tomtunguz.com/elo-improvement/
Nov 8, 2024
4
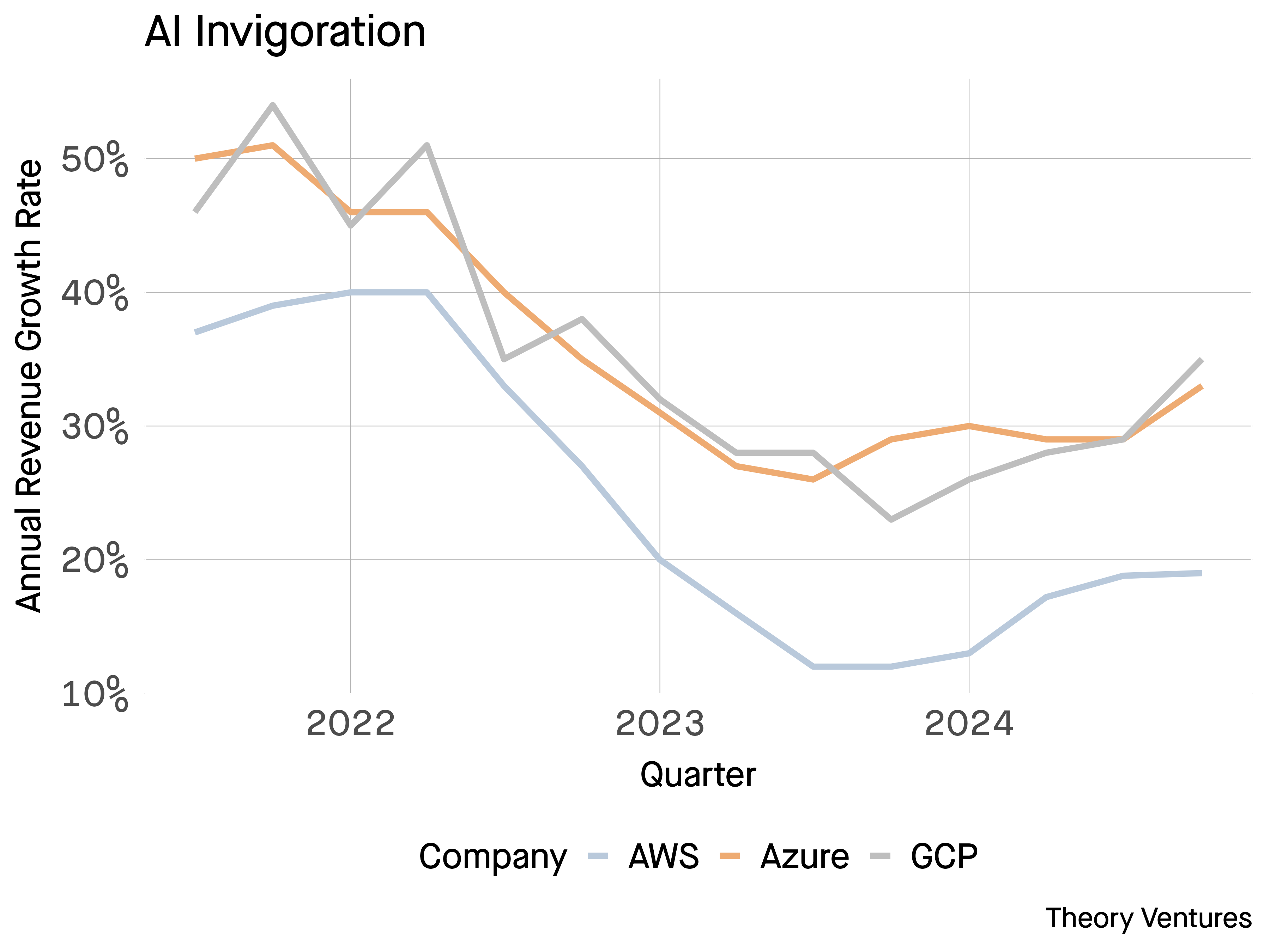
Profit Dollars per GPU Dollar by @ttunguz
tomtunguz.com/cloud-earnings-q3-24/?utm_source=Iterable&utm_medium=email&utm_campaign=newsletter-20241107
Nov 8, 2024
12

Trends in the Post-Modern Data Stack by @ttunguz
tomtunguz.com/disrupt-2024/
Nov 8, 2024
1
Cursor Has Raised $60M | Hacker News
news.ycombinator.com/item?id=41325543
Nov 5, 2024
2

The Race to Capture Value: Cloud Lessons for the AI Era | Andreessen Horowitz
a16z.com/cloud-lessons-for-the-ai-era/
Oct 22, 2024
1

Selling Is Hard Right Now. Here’s How to Win Business in the Gen AI Era.
a16z.com/selling-winning-new-business-genai/
Oct 22, 2024
12

Vertical SaaS: Now with AI Inside | Andreessen Horowitz
a16z.com/vertical-saas-now-with-ai-inside/
Oct 21, 2024
5

Humans > Software > SaaS > Outcome-aaS
www.bettercapital.vc/blog/humans-software-saas-outcome-aas/
Oct 4, 2024
1