
Mark Cuban: This Is One of the Most Common Mistakes I See Entrepreneurs Make
www.youtube.com/watch?v=hGK1yraNeXU&ab_channel=MichaelSimmons
Apr 14, 2022
1

40 Years of Stanford Research Found That People With This One Quality Are More Likely to Succeed
jamesclear.com/delayed-gratification
Apr 14, 2022
101

The Habits Guide: How to Build Good Habits and Break Bad Ones
jamesclear.com/habits
Apr 14, 2022
6
Why Pebble failed
medium.com/@ericmigi/why-pebble-failed-d7be937c6232
Apr 13, 2022
113

Jeff Bezos: Passion Is The Key To Success
www.youtube.com/watch?v=-tADdvQv_RE&ab_channel=MichaelSimmons
Apr 13, 2022
1

knowledge flows at the speed of trust
jarche.com/2022/03/knowledge-flows-at-the-speed-of-trust/
Apr 12, 2022
81
Learning in Public: The Most Effective Way to Learn
medium.com/@kazuki_sf_/learning-in-public-the-most-effective-way-to-learn-e14564d611b
Apr 12, 2022
112

How One Life Hack From A Self-Made Billionaire Leads To Exceptional Success
medium.com/accelerated-intelligence/how-one-life-hack-from-a-self-made-billionaire-leads-to-exceptional-success-48610e7a292
Apr 12, 2022
12

Growth Handbook - Framework, Mindset, Channels, and Virality | Glasp
glasp.co/articles/growth-handbook
Apr 9, 2022
21

Pragmatic Thinking and Learning by Andy Hunt: Summary & Notes - Nat Eliason
www.nateliason.com/notes/pragmatic-thinking-learning-andy-hunt
Apr 9, 2022
72

Every Entrepreneur Must Answer This Question, According To Elon Musk
www.youtube.com/watch?v=zqVILfmi0kQ&ab_channel=MichaelSimmons
Apr 8, 2022
1

Pre-Seed Funding: What It Is, How It Works & 7 Sources
www.failory.com/blog/pre-seed-funding
Apr 8, 2022
203

The No. 1 Predictor Of Career Success According To Network Science
medium.com/accelerated-intelligence/the-number-one-predictor-of-career-success-according-to-network-science-be7fcc8e9558
Apr 7, 2022
71

Self-Education: Teach Yourself Anything with the Sandbox Method - Nat Eliason
www.nateliason.com/blog/self-education
Apr 6, 2022
154
Memory & Learning Breakthrough: It Turns Out That The Ancients Were Right
medium.com/accelerated-intelligence/memory-learning-breakthrough-it-turns-out-that-the-ancients-were-right-7bbd3090d9cc
Apr 5, 2022
244

How To Study With A Highlighter: The Three Pitfalls That You Should Avoid
medium.goodnotes.com/three-pitfalls-to-avoid-when-studying-with-a-highlighter-2aa345e1e6eb
Apr 5, 2022
62
What is your Ikigai? · The View Inside Me
theviewinside.me/what-is-your-ikigai/
Apr 5, 2022
4
Authority & Merit
medium.com/@jack/authority-merit-80ad140f990b
Apr 5, 2022
1

Why Tacit Knowledge is More Important Than Deliberate Practice
commoncog.com/blog/tacit-knowledge-is-a-real-thing/
Apr 3, 2022
122

Programmable Notes
maggieappleton.com/programmatic-notes
Apr 3, 2022
61
The Anatomy of a Search Engine
infolab.stanford.edu/~backrub/google.html
Apr 2, 2022
9
Google Search Is Dying | DKB
dkb.io/post/google-search-is-dying
Apr 2, 2022
3

Building the Global Knowledge Graph: Dreaming the Dream for Roam Research - RoamBrain.com
roambrain.com/building-the-global-knowledge-graph/
Apr 1, 2022
91
To Organize The World's Information | DKB
dkb.io/post/organize-the-world-information
Apr 1, 2022
82

How Millennials Became The Burnout Generation
www.buzzfeednews.com/article/annehelenpetersen/millennials-burnout-generation-debt-work
Apr 1, 2022
202
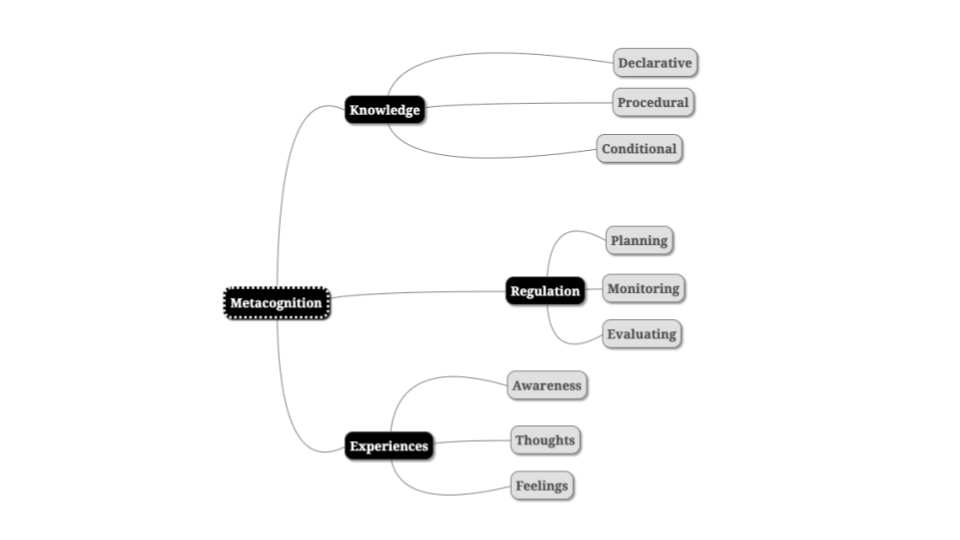
Metacognition: how to think about thinking
nesslabs.com/metacognition
Mar 31, 2022
6
Thinking in maps: from the Lascaux caves to knowledge graphs
nesslabs.com/thinking-in-maps
Mar 31, 2022
171
How A Quiet Developer Built Goodreads.com Into Book Community Of 2.6+ Million Members - with Otis Chandler - Business Podcast for Startups
mixergy.com/interviews/goodreads-otis-chandler/
Mar 29, 2022
81

Elizabeth Khuri Chandler Tells the Origin Story of Goodreads
lithub.com/elizabeth-khuri-chandler-tells-the-origin-story-of-goodreads/
Mar 29, 2022
54

Know Your Customers’ “Jobs to Be Done”
hbr.org/2016/09/know-your-customers-jobs-to-be-done
Mar 29, 2022
163

10 Lessons from Great Businesses | The Generalist
www.readthegeneralist.com/briefing/10-lessons
Mar 28, 2022
162

The Surprising Science of How Feelings Help You Think
www.gq.com/story/how-feelings-help-you-think
Mar 26, 2022
122

Marketing is More Than Growth: The 3 Parts of a Complete Strategy — Reforge
www.reforge.com/blog/marketing-is-more-than-growth
Mar 25, 2022
10

Productivity addiction: when we become obsessed with productivity
nesslabs.com/productivity-addiction
Mar 24, 2022
72

Link Building for SEO: The Definitive Guide (2022)
backlinko.com/link-building
Mar 24, 2022
81

Why Do People Collect Things?
glasp.substack.com/p/why-do-people-collect-things?s=w
Mar 23, 2022
7

While most people fight to learn “in-demand” skills, smart people are learning rare skills instead
medium.com/accelerated-intelligence/while-most-people-fight-to-learn-in-demand-skills-smart-people-are-secretly-learning-rare-skills-f9b26856c9d6
Mar 22, 2022
142

Keyword Research for SEO: The Definitive Guide (2022 Update)
backlinko.com/keyword-research
Mar 21, 2022
262

What is the Best Piece of Advice You Received?
debliu.substack.com/p/what-is-the-best-piece-of-advice?s=r
Mar 21, 2022
10
Testing Digital Highlighters
nocategories.net/ephemera/highlighters/
Mar 20, 2022
6

We Need a New Science of Progress
www.theatlantic.com/science/archive/2019/07/we-need-new-science-progress/594946/
Mar 20, 2022
81

Build Personal Moats
eriktorenberg.substack.com/p/build-personal-moats?s=r
Mar 17, 2022
131

People Who Have “Too Many Interests” Are More Likely To Be Successful According To Research
medium.com/accelerated-intelligence/modern-polymath-81f882ce52db
Mar 16, 2022
284

Stop thinking about productivity, and start thinking about focus.
dialed-ai.medium.com/stop-thinking-about-productivity-and-start-thinking-about-focus-d54d9008c622
Mar 16, 2022
183

Stop Overthinking Your Zettelkasten System: How To Get Started Writing Your First Notes
medium.com/friction-to-flow/stop-overthinking-your-zettelkasten-system-how-to-get-started-writing-your-first-notes-eeb2b0f060cc
Mar 15, 2022
71

The Elephant in the room: The myth of exponential hypergrowth
longform.asmartbear.com/docs/exponential-growth
Mar 15, 2022
111

ICED Theory - Growing Infrequent Products — Reforge
www.reforge.com/blog/iced-theory-growing-infrequent-products
Mar 15, 2022
112
Towards the Curator Economy
medium.com/@kazuki_sf_/towards-the-curator-economy-71e0c354e712
Mar 13, 2022
61

Learning how to learn
nesslabs.com/learning-how-to-learn
Mar 11, 2022
132

Compounding Knowledge - Farnam Street
fs.blog/compounding-knowledge/
Mar 11, 2022
103

Marie Curie: the power of sharing radical ideas with the world
nesslabs.com/marie-curie
Mar 10, 2022
72