
It’s time to take stock of your social life
www.vox.com/even-better/23744304/how-much-social-interaction-do-you-need-loneliness-burnout
Jun 19, 2023
143

Do More of What Already Works
jamesclear.com/checklist-solutions
Jun 17, 2023
41
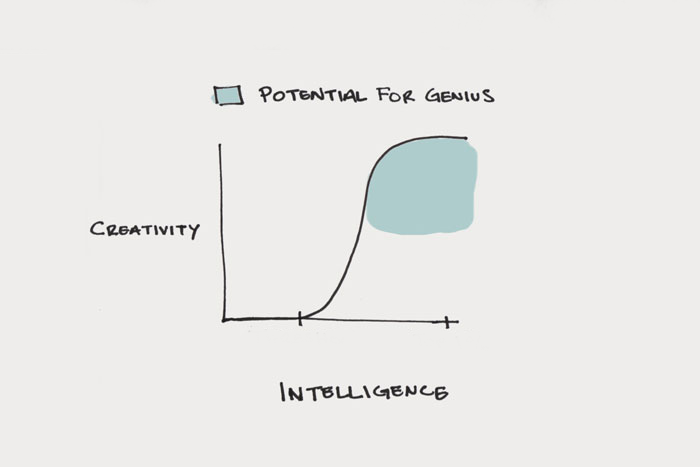
Creativity Is a Process, Not an Event
jamesclear.com/creative-thinking
Jun 16, 2023
183

The best, most frustrating quote about creativity
jayacunzo.com/blog/best-quote-on-creativity-ira-glass-gap
Jun 14, 2023
63

The Power of the Underdog
magazine.wharton.upenn.edu/issues/spring-summer-2022/the-power-of-the-underdog/
Jun 13, 2023
3

Function calling and other API updates
openai.com/blog/function-calling-and-other-api-updates
Jun 13, 2023
5

Paying Attention
collabfund.com/blog/paying-attention/
Jun 12, 2023
82

Knowledge Is Power—And Why You Should Share It
www.forbes.com/sites/katevitasek/2022/05/17/knowledge-is-powerand-why-you-should-share-it/?sh=7eb29585c7c6
Jun 12, 2023
4

Why AI Will Save The World
pmarca.substack.com/p/why-ai-will-save-the-world
Jun 7, 2023
213

AI Is Transforming Media Forever, Here's How
every.to/chain-of-thought/we-re-building-ai-into-our-media-business
Jun 6, 2023
132

Japan Goes All In: Copyright Doesn't Apply To AI Training
technomancers.ai/japan-goes-all-in-copyright-doesnt-apply-to-ai-training/
Jun 1, 2023
51
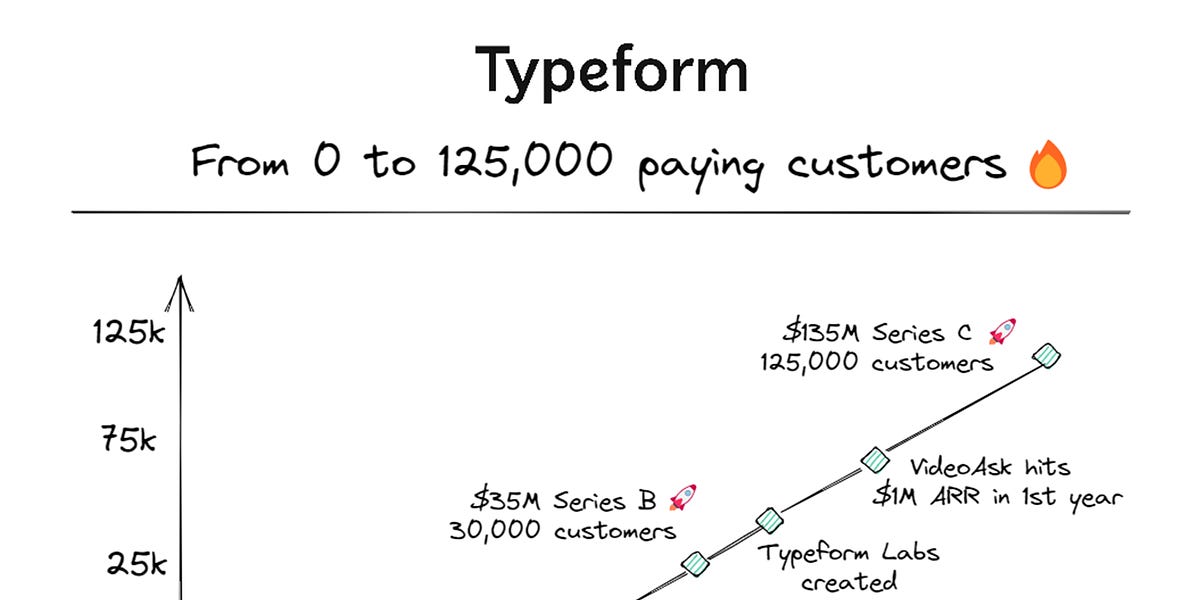
Typeform’s viral growth – and its disruption?
kylepoyar.substack.com/p/typeforms-viral-growth-and-its-disruption
Jun 1, 2023
162

In Online Ed, Content Is No Longer King—Cohorts Are
future.com/cohort-based-courses/
Jun 1, 2023
251

AI Canon | Andreessen Horowitz
a16z.com/2023/05/25/ai-canon/
May 26, 2023
1

How To Make Millions With Idea Sex - James Altucher
jamesaltucher.com/blog/how-to-make-millions-with-idea-sex/
May 25, 2023
31

Where Do Great Ideas Come From?
thegeneralist.substack.com/p/where-do-great-ideas-come-from
May 24, 2023
133

The Creator Economy Could Approach Half-a-Trillion Dollars by 2027
www.goldmansachs.com/intelligence/pages/the-creator-economy-could-approach-half-a-trillion-dollars-by-2027.html
May 17, 2023
41

How to Make Sure You Keep Growing and Learning
greatergood.berkeley.edu/article/item/how_to_make_sure_you_keep_growing_and_learning
May 15, 2023
8
The Personalization Wave, A Surge of Wildly Human-Intensive Non-Scalable Experiences, & Ideas Of The Month
www.implications.com/p/the-personalization-wave-a-surge
May 9, 2023
184
GPT-4 Is a Reasoning Engine
every.to/chain-of-thought/gpt-4-is-a-reasoning-engine
May 6, 2023
52
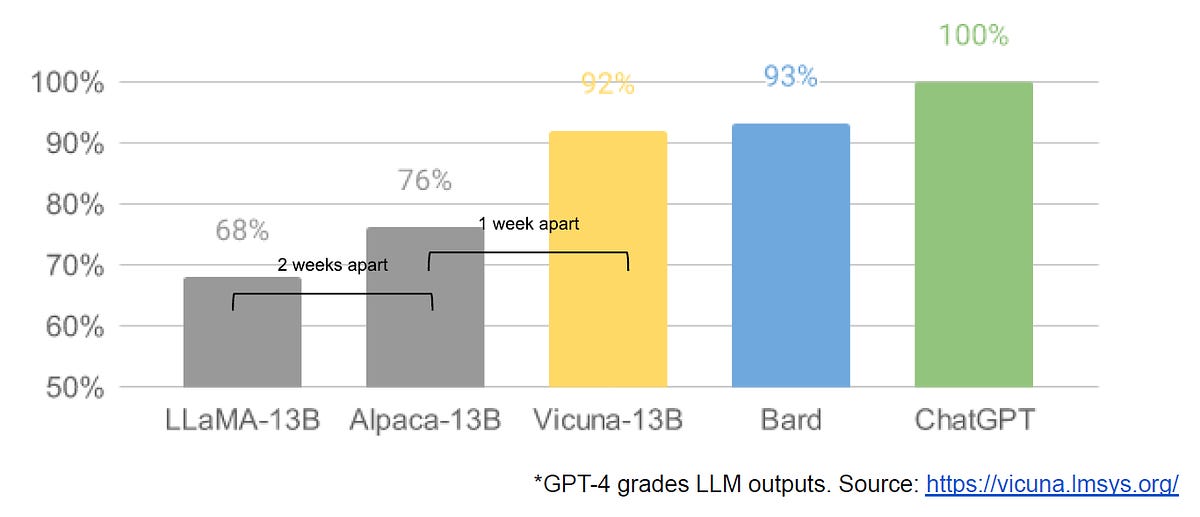
Google "We Have No Moat, And Neither Does OpenAI"
www.semianalysis.com/p/google-we-have-no-moat-and-neither
May 5, 2023
132

#PowerToTheConsumer: Insights from 30 Leading Consumer AI Founders, Operators and Thinkers
medium.com/crv-insights/powertotheconsumer-insights-from-30-leading-consumer-ai-founders-operators-and-thinkers-c3c56e6db04e
May 5, 2023
4

The Complete Beginners Guide To Autonomous Agents
www.mattprd.com/p/the-complete-beginners-guide-to-autonomous-agents
May 2, 2023
1

What is a Vector Database? | Pinecone
www.pinecone.io/learn/vector-database/
May 2, 2023
9

How to Pick a Career (That Actually Fits You) — Wait But Why
waitbutwhy.com/2018/04/picking-career.html
Apr 27, 2023
91

Intellectual Sparring Partners | The Curiosity Chronicle
www.sahilbloom.com/newsletter/intellectual-sparring-partners
Apr 25, 2023
5

How reading fiction can make you a better person
bigthink.com/neuropsych/reading-fiction-empathy-better-person/
Apr 19, 2023
9

Emotions Aren’t the Enemy of Good Decision-Making
hbr.org/2022/09/emotions-arent-the-enemy-of-good-decision-making
Apr 18, 2023
91
The Four Idols: Money, Power, Pleasure, & Fame | The Curiosity Chronicle
www.sahilbloom.com/newsletter/the-four-idols-money-power-pleasure-fame
Apr 17, 2023
61

Social’s Next Wave | The Generalist
www.generalist.com/briefing/socials-next-wave
Apr 13, 2023
162

How Search Works
www.slideshare.net/ahrefs/how-search-works-256157502
Apr 12, 2023
2

Why Write?
fs.blog/why-write/
Apr 11, 2023
62

Introducing Substack Notes
on.substack.com/p/introducing-notes
Apr 6, 2023
41

7 Powerful AI Tools For Creators and Entrepreneurs To Speed Up Your Success
medium.datadriveninvestor.com/7-powerful-ai-tools-for-creators-and-entrepreneurs-to-speed-up-your-success-1141c8a1f37e
Apr 6, 2023
31

2016 Letter to Shareholders
www.aboutamazon.com/news/company-news/2016-letter-to-shareholders
Apr 4, 2023
81
Existential risk, AI, and the inevitable turn in human history - Marginal REVOLUTION
marginalrevolution.com/marginalrevolution/2023/03/existential-risk-and-the-turn-in-human-history.html
Apr 4, 2023
3

Is Y Combinator worth the money (equity)? Brutally honest review of W22 batch experience
acecreamu.substack.com/p/is-y-combinator-worth-the-money
Mar 31, 2023
123

Sam Altman: OpenAI CEO on GPT-4, ChatGPT, and the Future of AI | Lex Fridman Podcast #367 - YouTube
www.youtube.com/watch?v=L_Guz73e6fw
Mar 29, 2023
335

For when someone says “I’ve seen this before, it didn’t work” — D'Arcy Coolican
www.darcycoolican.com/blog/ideamaze
Mar 27, 2023
9

Product Zeitgeist Fit: A Cheat Code for Spotting and Building the Next Big Thing | Andreessen Horowitz
a16z.com/2019/12/09/product-zeitgeist-fit/
Mar 27, 2023
135

The Age of AI has begun
www.gatesnotes.com/The-Age-of-AI-Has-Begun
Mar 22, 2023
10

The ____ Economy
darcy.substack.com/p/the-____-economy
Mar 20, 2023
92

GPT-4
openai.com/research/gpt-4
Mar 14, 2023
153

GPT-4
openai.com/product/gpt-4
Mar 14, 2023
4
Creativity is Productivity - Scott H Young
www.scotthyoung.com/blog/2023/02/28/creativity-is-productivity/
Mar 13, 2023
82

What is a sweep network and how does it allow Mercury to offer $1M in FDIC insurance?
mercury.com/blog/company-news/understanding-bank-sweep-network
Mar 13, 2023
72

We’re in a productivity crisis, according to 52 years of data. Things could get really bad.
medium.com/accelerated-intelligence/were-in-a-productivity-crisis-according-to-52-years-of-data-things-could-get-really-bad-5c7e53242a0
Mar 11, 2023
18

Substack: Empire of Narratives
thegeneralist.substack.com/p/substack
Mar 7, 2023
305
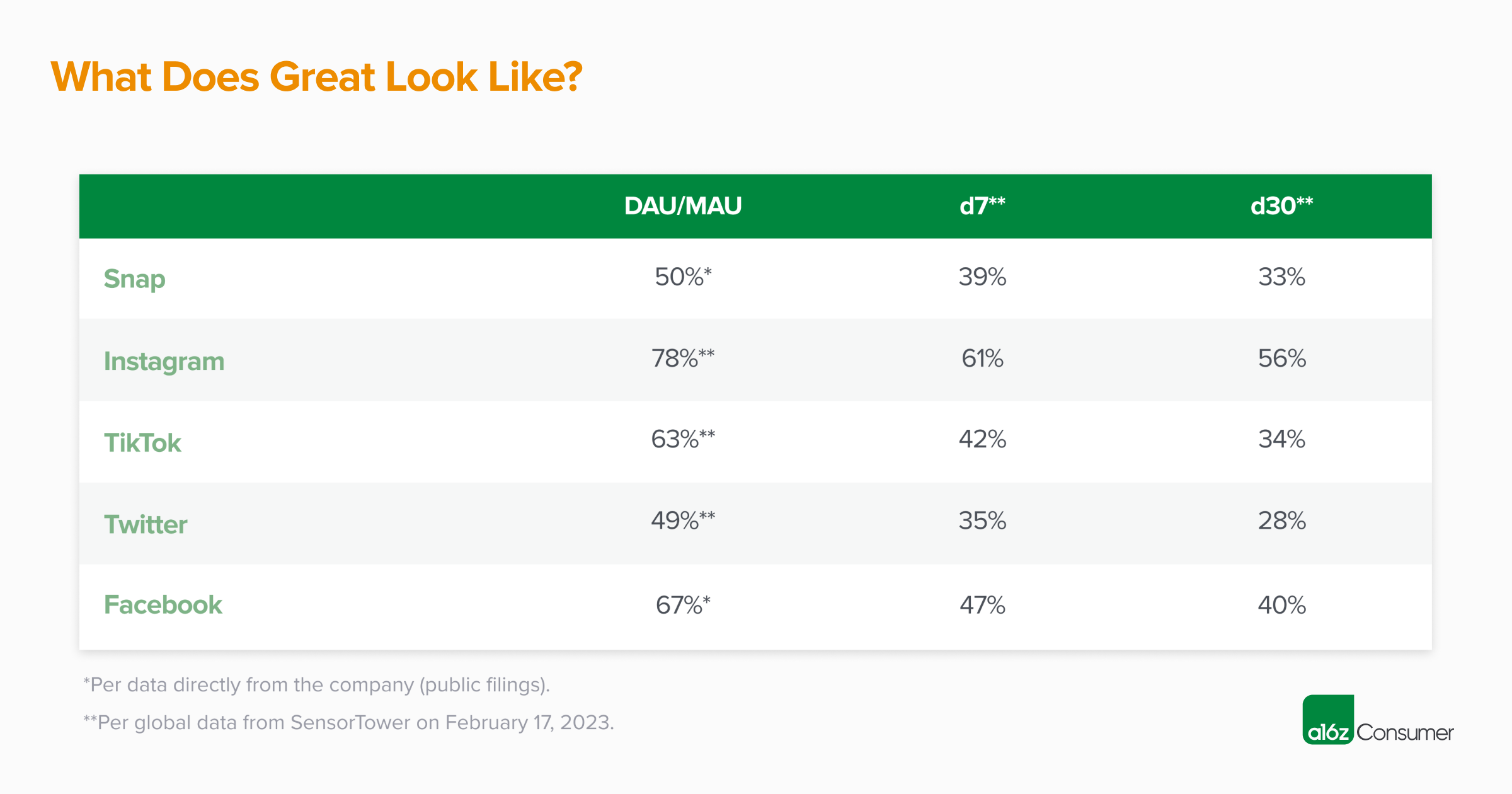
Do You Have Lightning In a Bottle? How to Benchmark Your Social App | Andreessen Horowitz
a16z.com/2023/03/03/how-to-benchmark-your-social-app/
Mar 4, 2023
162