Pmarchive · Luck and the Entrepreneur: The four kinds of luck
pmarchive.com/luck_and_the_entrepreneur.html
Sep 15, 2022
201
Most People Won’t
bryce.medium.com/most-people-won-t-ff0959cdefc6
Sep 15, 2022
3

Grow the Puzzle Around You
foundersatwork.posthaven.com/grow-the-puzzle-around-you
Sep 15, 2022
141

The Tail End — Wait But Why
waitbutwhy.com/2015/12/the-tail-end.html
Sep 15, 2022
4

Stay in the Game
www.albertbridgecapital.com/post/stay-in-the-game
Sep 15, 2022
1

8 Chrome Extensions You Probably Didn't Know Existed! - YouTube
www.youtube.com/watch?v=tyL0OwAgc_I
Sep 12, 2022
2

Immigrant-Entrepreneurs-and-Billion-Dollar-Companies.DAY-OF-RELEASE.2022.pdf
nfap.com/wp-content/uploads/2022/07/Immigrant-Entrepreneurs-and-Billion-Dollar-Companies.DAY-OF-RELEASE.2022.pdf
Sep 12, 2022
11

The Breaking of the Modern Mind: The Curse of the Attention Economy
hardfork.substack.com/p/the-breaking-of-the-modern-mind-the
Sep 11, 2022
4

Ron Conway at Startup School SV 2014 - YouTube
www.youtube.com/watch?v=qvHhhIfu7Lo
Sep 10, 2022
23

Re-decentralizing the Web, for good this time
ruben.verborgh.org/articles/redecentralizing-the-web/
Sep 9, 2022
6
From Users to (Sense)Makers: On the Pivotal Role of Stigmergic Social Annotation in the Quest for Collective SensemakingFrom Users to (Sense)Makers: On the Pivotal Role of Stigmergic Social Annotation in the Quest for Collective Sensemaking - 2205.06345.pdf
arxiv.org/pdf/2205.06345.pdf
Sep 9, 2022
9

The Knowledge-Creating Company
hbr.org/2007/07/the-knowledge-creating-company
Sep 9, 2022
7
AI Grant
aigrant.org/
Sep 8, 2022
7

Why do children die?
www.gatesnotes.com/Health/Why-do-children-die
Sep 6, 2022
11

The Long Tail: The Internet and the Business of Niche
digitalnative.substack.com/p/the-long-tail-the-internet-and-the
Sep 6, 2022
162
Incentive design and gamification for knowledge management - 1576487113_gh76.pdf
e-tarjome.com/storage/panel/fileuploads/2019-12-16/1576487113_gh76.pdf
Sep 6, 2022
15

Self-Taught AI Shows Similarities to How the Brain Works | Quanta Magazine
www.quantamagazine.org/self-taught-ai-shows-similarities-to-how-the-brain-works-20220811
Sep 3, 2022
7

A Wave Of Billion-Dollar Language AI Startups Is Coming
www.forbes.com/sites/robtoews/2022/03/27/a-wave-of-billion-dollar-language-ai-startups-is-coming/?sh=32af08f62b14
Sep 3, 2022
9

Incentive design and gamification for knowledge management
www.sciencedirect.com/science/article/abs/pii/S0148296319300992
Sep 3, 2022
2

DALL·E 2 and The Origin of Vibe Shifts
every.to/divinations/dall-e-2-and-the-origin-of-vibe-shifts
Aug 31, 2022
123

Google sets the bar for AI language models with PaLM
venturebeat.com/business/ai-weekly-google-sets-the-bar-for-ai-language-models-with-palm/
Aug 31, 2022
8

AI Revolution - Transformers and Large Language Models (LLMs)
blog.eladgil.com/2022/08/ai-revolution-transformers-and-large.html
Aug 31, 2022
111

Alphabet (Google)
www.kleinerperkins.com/case-study/google/
Aug 30, 2022
51

How Humans Grew Acorn Brains
longnow.org/ideas/02022/07/29/how-humans-grew-acorn-brains/
Aug 25, 2022
15

The Janusian Process in Creativity
www.psychologytoday.com/us/blog/creative-explorations/201506/the-janusian-process-in-creativity
Aug 24, 2022
8
Yet Another Article About Extensions
medium.com/taking-notes/yet-another-article-about-extensions-6aeca0225bfc
Aug 24, 2022
61

How to Use Tokenization to Drive Growth: 7 Lessons From a Company That's Killing It - Tascha Labs
taschalabs.com/how-to-use-tokenization-for-business-growth-7-lessons-from-a-successful-project/
Aug 24, 2022
202

CAC: Customer Acquisition Chaos
digitalnative.substack.com/p/cac-customer-acquisition-chaos
Aug 24, 2022
173

Five Pieces of Writing Wisdom Most Writers Don’t Learn Until 5 Years In
writingcooperative.com/five-pieces-of-writing-wisdom-most-writers-dont-learn-until-5-years-in-d57b33dab22c
Aug 24, 2022
9
Larry Page: Where's Google going next? | TED Talk
www.ted.com/talks/larry_page_where_s_google_going_next/transcript
Aug 23, 2022
71
Habit trackers: does tracking your habits actually work?
nesslabs.com/habit-trackers
Aug 22, 2022
101
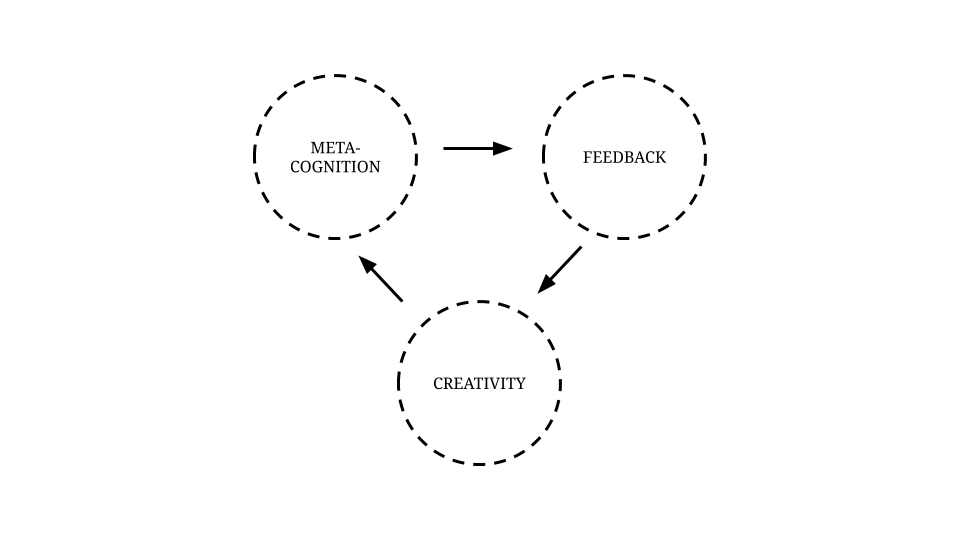
WIP: the case for sharing your work in public
nesslabs.com/work-in-public
Aug 19, 2022
122

One million strong
on.substack.com/p/one-million-strong
Aug 17, 2022
5

A guide to curation in community
rosie.land/posts/a-guide-to-curation-in-community/
Aug 16, 2022
11
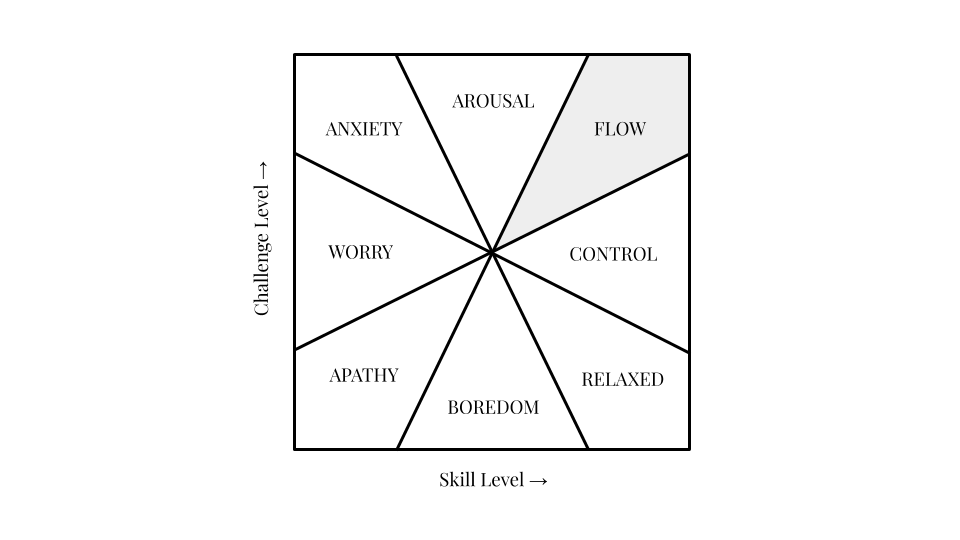
How to get in the flow
nesslabs.com/flow
Aug 16, 2022
7

How to find new things to learn
tamethestars.wordpress.com/2022/08/16/how-to-find-new-things-to-learn/
Aug 16, 2022
41

How to monetize the curation economy, social communities & online learning
whizzoe.substack.com/p/how-to-monetize-the-curation-economy
Aug 16, 2022
51

43 life lessons at age 43
radreads.co/43-life-lessons-at-age-43/
Aug 15, 2022
9

Teens, Social Media and Technology 2022
www.pewresearch.org/internet/2022/08/10/teens-social-media-and-technology-2022/
Aug 15, 2022
81

Why NFT Creators Are Going cc0
a16zcrypto.com/cc0-nft-creative-commons-zero-license-rights/
Aug 15, 2022
15
How Long Does Copyright Protection Last? (FAQ) | U.S. Copyright Office
www.copyright.gov/help/faq/faq-duration.html
Aug 15, 2022
1

Should you sell newsletter sponsorships?
ghost.org/resources/newsletter-sponsorships/
Aug 15, 2022
101

TfT #2 / Upgrading 5400 years old tech: tools for better reading
www.getrevue.co/profile/tft/issues/tft-2-upgrading-5400-years-old-tech-tools-for-better-reading-1294493
Aug 15, 2022
6

Identity-Based Habits: How to Actually Stick to Your Goals This Year
jamesclear.com/identity-based-habits
Aug 10, 2022
11

How I approach structured learning after school – Radi's Blog
radi.blog/how-i-approach-structured-learning-after-school/
Aug 10, 2022
94

Airbnb Pitch Deck Template | Free PDF & PPT Download
slidebean.com/templates/airbnb-pitch-deck
Aug 10, 2022
1

Sequoia Capital Pitch Deck Template
www.slideshare.net/PitchDeckCoach/sequoia-capital-pitchdecktemplate
Aug 9, 2022
1

Glasp – Capturing Information from the Web
tamethestars.wordpress.com/2022/08/02/glasp-capturing-information-from-the-web/
Aug 9, 2022
41
The death of the newsfeed — Benedict Evans
www.ben-evans.com/benedictevans/2018/4/2/the-death-of-the-newsfeed
Aug 9, 2022
7
Do Things, Tell People.
carl.flax.ie/dothingstellpeople.html
Aug 9, 2022
4