
The Web3 Playbook: Using Token Incentives to Bootstrap New Networks | Future
future.a16z.com/the-web3-playbook-using-token-incentives-to-bootstrap-new-networks/
Dec 12, 2021
6
Engagement Drives Stickiness Drives Retention Drives Growth
medium.com/sequoia-capital/engagement-drives-stickiness-drives-retention-drives-growth-3a6ac53a7a00
Dec 8, 2021
102

The Psychology of Startup Growth
www.nfx.com/post/psychology-startup-growth/
Dec 7, 2021
23

Presentations — Benedict Evans
www.ben-evans.com/presentations
Dec 7, 2021
1

Sifting the Essential from the Non-Essential
fs.blog/albert-einstein-simplicity/
Dec 6, 2021
92
The Token Disconnect
www.stephendiehl.com/blog/disconnect.html
Dec 3, 2021
91
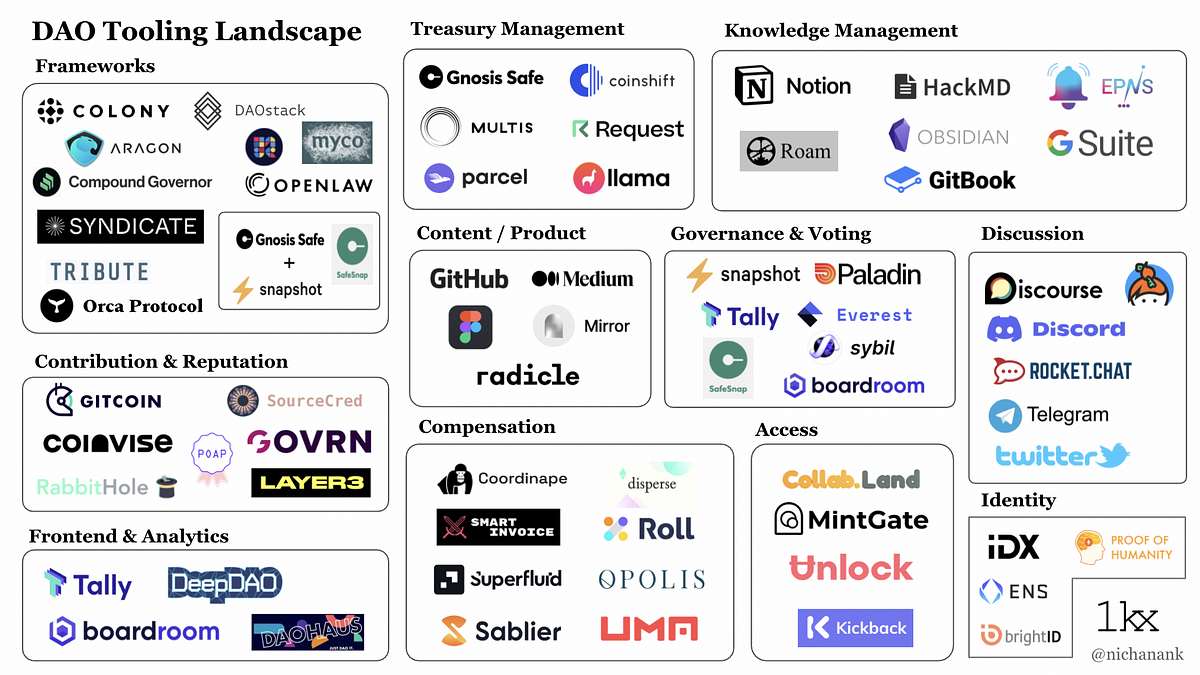
Organization Legos: The State of DAO Tooling
medium.com/1kxnetwork/organization-legos-the-state-of-dao-tooling-866b6879e93e
Dec 3, 2021
21

Capturing cross-selling synergies in M&A
www.mckinsey.com/business-functions/m-and-a/our-insights/capturing-cross-selling-synergies-in-ma
Dec 2, 2021
162
How to take smart notes (Ahrens, 2017) - LessWrong
www.lesswrong.com/posts/T382CLwAjsy3fmecf/how-to-take-smart-notes-ahrens-2017
Dec 1, 2021
151

Zettelkasten — How One German Scholar Was So Freakishly Productive
writingcooperative.com/zettelkasten-how-one-german-scholar-was-so-freakishly-productive-997e4e0ca125
Nov 30, 2021
233

The Hook Model: How to Manufacture Desire in 4 Steps
www.nirandfar.com/how-to-manufacture-desire/
Nov 30, 2021
12

Startup Metrics for Pirates
www.slideshare.net/dmc500hats/startup-metrics-for-pirates-long-version
Nov 29, 2021
2

Jeremy Levine's backstory on Pinterest–from Series A to IPO
www.bvp.com/atlas/pinterest-ipo
Nov 28, 2021
52

Fat Protocols | Union Square Ventures
www.usv.com/writing/2016/08/fat-protocols/
Nov 26, 2021
12

Digital Economies, Gaming, and IP Legos
digitalnative.substack.com/p/digital-economies-gaming-and-ip-legos
Nov 24, 2021
121
How Microsoft’s Human Insights Library Creates a Living Body of Knowledge
medium.com/microsoft-design/how-microsofts-human-insights-library-creates-a-living-body-of-knowledge-fff54e53f5ec
Nov 24, 2021
9

All Our Patent Are Belong To You
www.tesla.com/blog/all-our-patent-are-belong-you
Nov 23, 2021
4

A beginner's guide to social tokens — Mirror
linda.mirror.xyz/4PDBWBMpFFPVEsP5EGgg5to2AyEpEHEXasq_K0b-yYk
Nov 23, 2021
9

The Year Of The Decacorn: 2021 Shatters Records For Number Of New Startups Valued At $10B+
news.crunchbase.com/news/decacorn-startups-2021-global-record-data-charts/
Nov 23, 2021
6

(📜,📜), 👁👄👁, & the power of "Nametagging"
constine.substack.com/p/nametagging
Nov 22, 2021
4

An Incomplete Guide to Rollups
vitalik.ca/general/2021/01/05/rollup.html
Nov 22, 2021
331
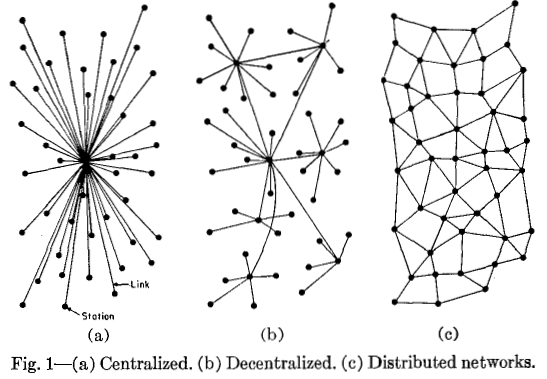
The Meaning of Decentralization
medium.com/@VitalikButerin/the-meaning-of-decentralization-a0c92b76a274
Nov 22, 2021
18
DAOs, A Canon - Future
future.a16z.com/dao-canon/
Nov 22, 2021
1

10 Traits of Great PMs
medium.com/@noah_weiss/10-traits-of-great-pms-a7776cd3d9cd
Nov 20, 2021
7

How To Evolve As a Product Manager
medium.com/agileinsider/how-to-evolve-as-a-product-manager-13c3e06198d4
Nov 19, 2021
5

'Play-to-Earn' Gaming and How Work is Evolving in Web3 - Future
future.a16z.com/podcasts/play-to-earn-gaming-and-how-work-is-evolving-in-web3/
Nov 19, 2021
173

7 essential characteristics of a product manager
jocatorres.medium.com/7-essential-characteristics-of-a-product-manager-77684e63877c
Nov 18, 2021
8

Highlighting – Learning Center
learningcenter.unc.edu/tips-and-tools/using-highlighters/
Nov 18, 2021
12

Social Tokens and Creator-Centric Economies
digitalnative.substack.com/p/social-tokens-and-creator-centric
Nov 18, 2021
151

A Guide to Gen Z Through TikTok Trends, Emojis, & Language
digitalnative.substack.com/p/a-guide-to-gen-z-through-tiktok-trends
Nov 17, 2021
161

Bitcoin Killed The King & Now Network Effects Will Determine Its Future
www.nfx.com/post/network-effects-bitcoin/
Nov 17, 2021
291
.jpg)
ODX Investment Memo
www.beondeck.com/fund-memo
Nov 17, 2021
5

✍️ Substack
read.first1000.co/p/-substack
Nov 17, 2021
161

How Users Read on the Web
www.nngroup.com/articles/how-users-read-on-the-web/
Nov 16, 2021
51

The Top 3 Most Effective Ways to Take Notes While Reading
fs.blog/taking-notes-while-reading/
Nov 16, 2021
81

The 7 Biggest Reasons Why Online Communities Fail
meetwaves.medium.com/the-7-biggest-reasons-why-online-communities-fail-420fc5ba566d
Nov 14, 2021
162

The Future of Search: A Conversation with Sridhar Ramaswamy, CEO and Co-founder of Neeva and a Venture Partner at Greylock. - Thought Economics
thoughteconomics.com/sridhar-ramaswamy/
Nov 13, 2021
144

Lifelong Learning
fs.blog/lifelong-learning/
Nov 12, 2021
8

Accelerated Learning: Learn Faster and Remember More - Farnam Street
fs.blog/learning/
Nov 11, 2021
161
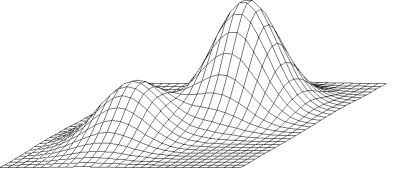
Climbing the wrong hill
cdixon.org/2009/09/19/climbing-the-wrong-hill
Nov 11, 2021
2

The Feynman Learning Technique - Farnam Street
fs.blog/feynman-learning-technique/
Nov 11, 2021
231

How Do Rocket Scientists Learn? (aka, knowledge management lessons learned at Goddard, NASA) - GovLoop
www.govloop.com/community/blog/how-do-rocket-scientists-learn-aka-knowledge-management-lessons-learned-at-goddard-nasa/
Nov 10, 2021
112

The internet needs better rules, not stricter referees
on.substack.com/p/new-rules
Nov 10, 2021
4

Who Is Ann Hiatt, the Assistant Behind Some of Silicon Valley’s Top Executives?
marketrealist.com/p/ann-hiatt-executive-assistant-bezos/
Nov 10, 2021
2
Why We’re Building A New Product To Change The Way We Read Online
medium.com/@otown/why-were-building-a-new-product-to-change-the-way-we-read-online-c9c557162f0e
Nov 10, 2021
3
12 Things about Product-Market Fit | Future
future.a16z.com/about-product-market-fit/
Nov 10, 2021
262

Product Hunt, meet Hyper | Product Hunt
www.producthunt.com/stories/product-hunt-meet-hyper
Nov 9, 2021
2

Why most online communities fail — and how to build a better one!
medium.com/@justinemoore_85088/why-most-online-communities-fail-and-how-to-build-a-better-one-b76557136e93
Nov 9, 2021
15
Learn In Public: The fastest way to learn ∊ swyx.io
www.swyx.io/learn-in-public/
Nov 8, 2021
81

Learning in public
jarche.com/2010/11/learning-in-public/
Nov 8, 2021
61

Learning is a Lifelong Process
glasp.substack.com/p/learning-is-a-lifelong-process
Nov 6, 2021
121