(1) https://arxiv.org/abs/2406.13121 - Search / X
x.com/search?q=https%3A%2F%2Farxiv.org%2Fabs%2F2406.13121&src=typed_query&f=top
Jun 26, 2024
1
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
arxiv.org/abs/2406.13121
Jun 26, 2024
1
(2) Posts liked by mark erdmann (@markerdmann) / X
x.com/markerdmann/likes
Jun 25, 2024
2
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
arxiv.org/abs/2406.11695
Jun 25, 2024
1
(1) Dan Hendrycks on X: "Nat's right so I think I'm going to make 2-3 more benchmarks to replace MMLU and MATH." / X
x.com/DanHendrycks/status/1804929811703591345
Jun 24, 2024
1
(2) Eugene Yan (SF 22 - 28 June) on X: "i previously spoke to a team who only used embedding-based retrieval. i suggested, insisted, they try lexical search. at our next chat, they shared that 80% of the relevant docs now come from lexical search. i.e., without lexical search they were missing 80% of the juice for RAG. https://t.co/2N92Xygw1G" / X
x.com/eugeneyan/status/1804270554033328359
Jun 21, 2024
1
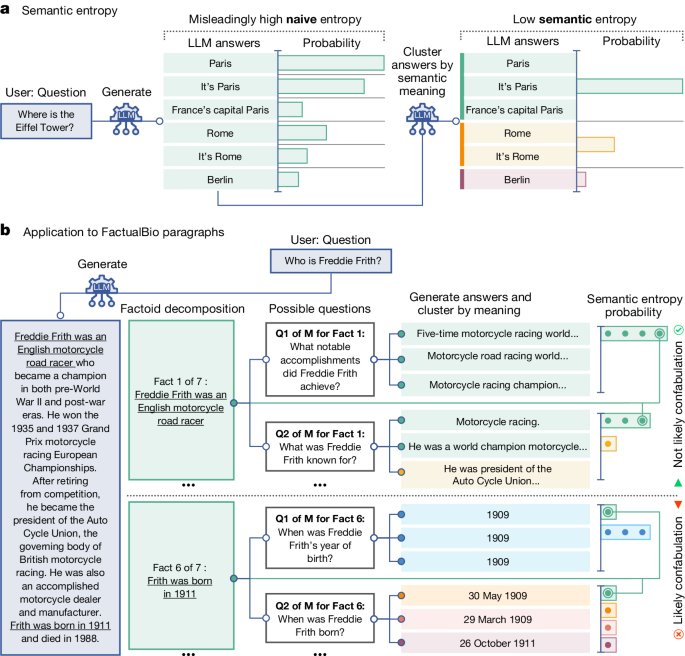
Detecting hallucinations in large language models using semantic entropy - Nature
www.nature.com/articles/s41586-024-07421-0
Jun 21, 2024
1
(2) Andrej Karpathy on X: "The way to think about asking a factual question to an LLM is that it's a bit like asking a person who read about the topic previously, but they are not allowed to reference any material and have to answer just from memory. LLMs are a lot better at memorizing than humans, but the" / X
x.com/karpathy/status/1804208334033371213
Jun 21, 2024
1
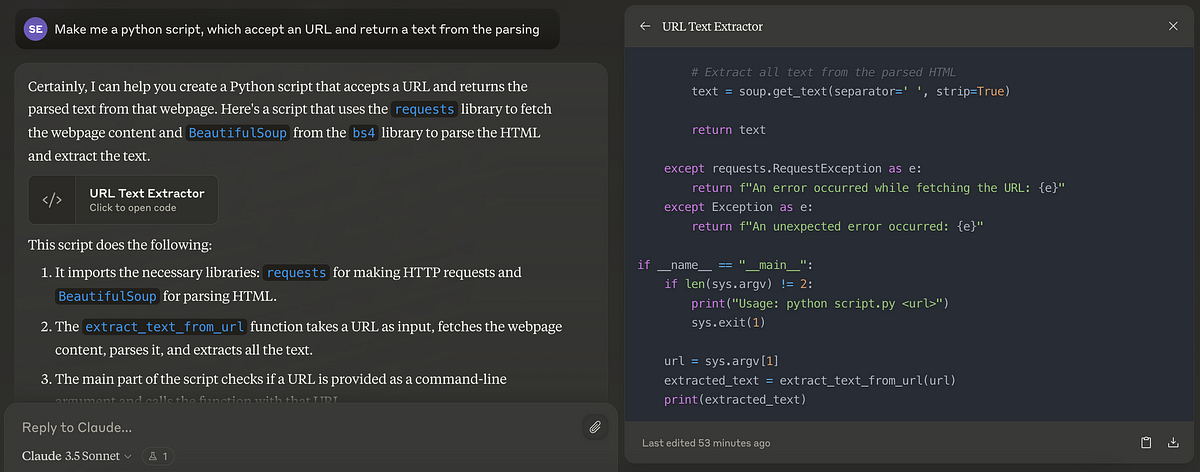
How to use Claude’s artifacts
medium.com/@simeon.emanuilov/how-to-use-claudes-artifacts-908835dbd96a
Jun 21, 2024
1
(1) Keyon Vafa on X: "New paper: How can you tell if a transformer has the right world model? We trained a transformer to predict directions for NYC taxi rides. The model was good. It could find shortest paths between new points But had it built a map of NYC? We reconstructed its map and found this: https://t.co/5z6sglnRIQ" / X
x.com/keyonV/status/1803838591371555252
Jun 20, 2024
2
2406.04692v1.pdf
arxiv.org/pdf/2406.04692
Jun 20, 2024
1

Aqua Voice - Voice-only Document Editor
withaqua.com/?ref=upstract.com
Jun 20, 2024
1
(1) Rob Wiblin on X: ""The results were otherworldly. Claude is fully capable of acting as a Supreme Court Justice right now. When used as a law clerk, Claude is easily as insightful and accurate as human clerks, while towering over humans in efficiency." https://t.co/tfdYtHSqnT https://t.co/83t85g5Wtp" / X
x.com/robertwiblin/status/1803388400084381787
Jun 20, 2024
1

NeurIPS-2021-attention-approximates-sparse-distributed-memory-Paper.pdf
proceedings.neurips.cc/paper_files/paper/2021/file/8171ac2c5544a5cb54ac0f38bf477af4-Paper.pdf
Jun 19, 2024
1
Lienid on X: "@mikeknoop been clear for a while that transformers have nailed associative memory. it even maps to a biologically plausible mechanism. frankly i’m not sure how people haven’t come to this conclusion yet https://t.co/remVwHBlYd" / X
x.com/0xLienid/status/1803530958207066114
Jun 19, 2024
1
Mike Knoop on X: "If superintelligence is human-level skill acquisition (AGI) plus narrow super-human characteristics, like memorization or inference speed, this is plausibly within reach. The former still requires new 0 to 1 ideas (see ARC Prize) but the latter already exists." / X
x.com/mikeknoop/status/1803528066616246478
Jun 19, 2024
1
Rohan Paul on X: "Transformer models can learn robust reasoning skills (beyond those of GPT-4-Turbo and Gemini-1.5-Pro) through a stage of training dynamics that continues far beyond the point of overfitting (i.e. with 'Grokking') 🤯 For a challenging reasoning task with a large search space,… https://t.co/Tl9bND5PHq" / X
x.com/rohanpaul_ai/status/1803478727067603055
Jun 19, 2024
1
Gary Basin 🍍 on X: "Why deep learning is ngmi in one graph https://t.co/lZwvEnXy8H" / X
x.com/garybasin/status/1802465723215737112
Jun 19, 2024
1
davidad 🎇 on X: "When @GaryMarcus and others (including myself) say that LLMs do not “reason,” we mean something quite specific, but it’s hard to put one’s finger on it, until now. Specifically, Transformers do not generalize algebraic structures out of distribution." / X
x.com/davidad/status/1802576341470216362
Jun 19, 2024
1
abhav on X: "Something weird is afoot. quick story involving: - open source "reasoning" SOTA LLM (only 7B params, and from china!) - big math doing small math - a $1M opportunity well, almost $1m and that is really tough. anyway, strap in 🍿🧵" / X
x.com/abhav_k/status/1802572167617626399
Jun 19, 2024
1
Hesam on X: "Reasoning with LLM is Hard! Large Language Models need help with generalized reasoning capabilities, and a key factor is how we prompt them. 📌 Traditional prompting methods such as Chain-of-Thought (CoT) or Tree-of-Thought (ToT) often require multiple assumptions or numerous… https://t.co/XtRVXNSydX" / X
x.com/itsHesamSheikh/status/1801934604334477355
Jun 19, 2024
1
AlphaMath Almost Zero: process Supervision without process
arxiv.org/abs/2405.03553
Jun 19, 2024
1
Aran Komatsuzaki on X: "@jeremyphoward Btw there are many other recent papers with LLM + MCTS for reasoning with successful results. Here are some interesting ones: - https://t.co/TpE92UMx2C - https://t.co/1Kh8rVyTat" / X
x.com/arankomatsuzaki/status/1803482585378726379
Jun 19, 2024
1
Alessio Fanelli on X: "How AI is eating Finance 📈 @vagabondjack is back on @latentspacepod! He shared all the AI Engineering wisdom he acquired while turning LLMs into AI thought partners @brightwaveio for customers with >$120B under management 💰 - Why he lost faith in long context windows - 3 https://t.co/AKJ82amHDC" / X
x.com/FanaHOVA/status/1800553625607155856
Jun 19, 2024
1
Xing Han Lu on X: "Announcing ⚡BM25S, a fast lexical retrieval library! 🏎️ Up to 500x faster than the most popular Python lib, matches @Elastic search (BM25 default) 🤗 First BM25 library that is directly integrated with @huggingface hub: load or save in 1 line! GitHub: https://t.co/iuQleXIGgX https://t.co/trNv0QbUao" / X
x.com/xhluca/status/1803100958408241597
Jun 19, 2024
1
Naomi Saphra on X: "Modern generative models are trained to imitate human experts, but can they actually beat those experts? Our new paper uses imitative chess agents to explore when a model can "transcend" its training distribution and outperform every human it's trained on. https://t.co/oKsIh5nVBk https://t.co/rA3TzmIXm7" / X
x.com/nsaphra/status/1803114822445465824
Jun 19, 2024
1
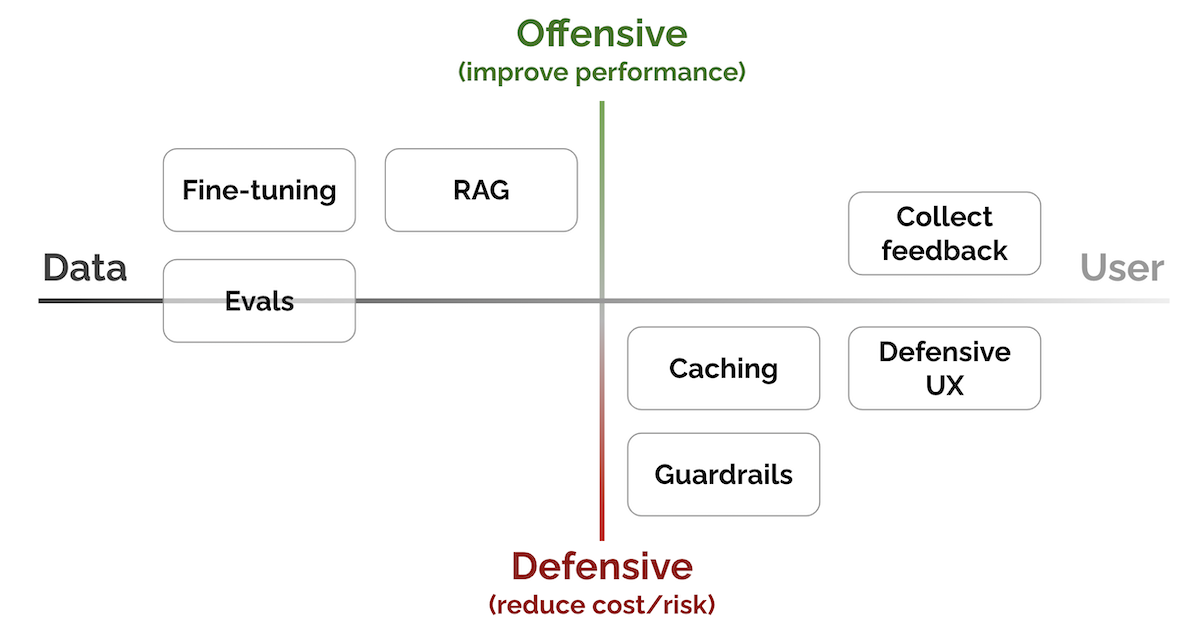
Patterns for Building LLM-based Systems & Products
eugeneyan.com/writing/llm-patterns/
Jun 19, 2024
1
Arvind Narayanan on X: "Tired: train/test leakage. Wired: benchmark contamination. Inspired: resample until answer is correct." / X
x.com/random_walker/status/1803392358093857127
Jun 19, 2024
1
(1) Alex Cheema - e/acc on X: "Llama 3 running locally on iPhone with MLX Built by @exolabs_ team @mo_baioumy h/t @awnihannun MLX & @Prince_Canuma for the port https://t.co/4swkM7mOfI" / X
x.com/ac_crypto/status/1781061013716037741
Jun 19, 2024
1
2406.11741v1.pdf
arxiv.org/pdf/2406.11741
Jun 19, 2024
1
Context caching | Google AI for Developers | Google for Developers
ai.google.dev/gemini-api/docs/caching?lang=python
Jun 19, 2024
1
x.com/johnathanbi/status/1803096216299090267?s=12
Jun 19, 2024
Pass@k or Pass@1? · Issue #1 · trotsky1997/MathBlackBox
github.com/trotsky1997/MathBlackBox/issues/1
Jun 18, 2024
1
quickwit-oss/tantivy: Tantivy is a full-text search engine library inspired by Apache Lucene and written in Rust
github.com/quickwit-oss/tantivy
Jun 18, 2024
1
Olympiad Solutions - Search / X
x.com/search?q=Olympiad%20Solutions&src=typed_query
Jun 18, 2024
1

The 100 Rep Squat Challenge
kettlebellaerobics.substack.com/p/the-100-rep-squat-challenge
Jun 18, 2024
1

Applied LLMs - What We’ve Learned From A Year of Building with LLMs
applied-llms.org/
Jun 18, 2024
1
(1) Terry Yue Zhuo on X: "In the past few months, we’ve seen SOTA LLMs saturating basic coding benchmarks with short and simplified coding tasks. It's time to enter the next stage of coding challenge under comprehensive and realistic scenarios! -- Here comes BigCodeBench, benchmarking LLMs on solving… https://t.co/w3Z6N5wnVk" / X
x.com/terryyuezhuo/status/1803076834520945117
Jun 18, 2024
1
(2) François Chollet on X: "I believe that program synthesis will solve reasoning. And I believe that deep learning will solve program synthesis (by guiding a discrete program search process). But I don't think you can go all that far with just prompting a LLM to generate end-to-end Python programs (even…" / X
x.com/fchollet/status/1803096195684012371
Jun 18, 2024
1
Caiming Xiong on X: "🎆I am pleased to announce the release of the latest version of the Salesforce Embedding Model (SFR-embedding-v2), which has reclaimed the top-1 position on the MTEB benchmark. ✨ Key Highlights: 🥇 Achieved the distinction of being the second model to surpass a 70+ performance… https://t.co/ucs4gXfp1v" / X
x.com/CaimingXiong/status/1802879572385714496
Jun 18, 2024
1

Debunking the Chessboard: Confronting GPTs Against Chess Engines to Estimate Elo Ratings and Assess Legal Move Abilities
blog.mathieuacher.com/GPTsChessEloRatingLegalMoves/
Jun 18, 2024
1
Beyond the Basics of Retrieval for Augmenting Generation – Parlance
parlance-labs.com/education/rag/ben.html
Jun 18, 2024
1
TaskMeAnything
www.task-me-anything.org/
Jun 18, 2024
2
John David Pressman on X: "My problem with "transformers don't generalize algebraic structures and therefore don't reason" is that while I agree this is a real limitation there are important aspects of reason which these models in fact do and other methods don't. We may need to divide "reason" up." / X
x.com/jd_pressman/status/1802835378451185733
Jun 18, 2024
1
François Chollet on X: "@RyanPGreenblatt @TomDAAVID @AndrewTBurks @dwarkesh_sp This isn't reasoning, it's intuition. Intuition is a fast, perception-like, inexact, approximate way of navigating a complex space. Your LLM has "intuition" over the space of program, which can be used to fight combinatorial complexity and make discrete program search more…" / X
x.com/fchollet/status/1802790666420035646
Jun 18, 2024
1
(1) François Chollet on X: "@mahaoo_ASI @wintermoat SOTA did not go from 35% to 50%. The 50% is on the evaluation set, the 35% is on the private test set. The solution that does ~35% on the private test set also did ~50% on the evaluation set, so 50% on the eval set is not clearly a new SOTA (it might be, but it isn't clear)" / X
x.com/fchollet/status/1802807579489468846
Jun 18, 2024
1
(1) Warp on X: "Type plain English on the command line. Accomplish any dev task. This is the command line for the AI era. New Agent Mode is available today. https://t.co/ptqib32w8o" / X
x.com/warpdotdev/status/1802736163507118387
Jun 18, 2024
1