Posts / X
x.com/i/timeline
Jul 15, 2024
4
Soami Kapadia on X: "Mixture of Agents on Groq Introducing a fully configurable, Mixture-of-Agents framework powered by @GroqInc using @LangChainAI You can configure your own MoA version using the @streamlit UI through the framework. details + links below👇🧵 https://t.co/nItnqbPtgi" / X
x.com/KapadiaSoami/status/1811657156082712605
Jul 13, 2024
3
(1) Ted Werbel on X: "Few things pretty obvious to a few AI researchers but that most don't want to believe: 1. 90% of the most impactful AI research is already on arxiv, x, or company blog posts 2. q* aka strawberry = STaR (self-taught reasoners) with dynamic self-discover + something like DSPy for" / X
x.com/tedx_ai/status/1811945091696853431
Jul 13, 2024
1
ben on X: "super interesting report on @openai's revenue they make 5x more from ChatGPT than they make from every single product that is built on top of OpenAI, in the entire world, combined https://t.co/JinXW4GHZY https://t.co/HTY4c9PqVe" / X
x.com/benhylak/status/1811448374349943263
Jul 12, 2024
1
Patrick Hsu on X: "Collaborate with people who have a strong sense of aesthetic This is surprisingly underappreciated" / X
x.com/pdhsu/status/1811416100393083002
Jul 12, 2024
1
Yifei Hu on X: "Releasing TF-ID: Table/Figure Identifier for academic papers. SoTA performance: 98%+ sucess rate for perfect table/figure detection 📈 mit license: free for any use cases ✅ 2 sizes: 0.23B and 0.77B 📏 2 variants: with or without caption text 🛠️ Finetuned on Florence 2 with https://t.co/kEoLCVFaRs" / X
x.com/hu_yifei/status/1811187540009042417
Jul 12, 2024
1
(1) xjdr on X: "Claude Power Move (CPM): Come up with an abstract idea "Help me create a step-by-step plan to <do x> and in order to accomplish <y goal>". Send that to sonnet 3.5 for the reasoning engine. Take the sonnet 3.5 output and feed it into opus with a "Please elaborate and improve" / X
x.com/_xjdr/status/1811470145426194602
Jul 12, 2024
1
(1) Tanay Jaipuria on X: "Software IPOs by Year 😲 via @avenirgrowth https://t.co/j1UAeWomCQ" / X
x.com/tanayj/status/1811517130963083408
Jul 12, 2024
1
Ethan Mollick on X: "An experiment shows temperature has different effects on test-taking for men vs. women. For verbal tests, women beat men when it is over 70° F (maxing at 90°). In math, men & women do the same when its 80°. They suggest setting office thermostats higher! https://t.co/JJnSXs4VV4 https://t.co/LcxbIpdcqR" / X
x.com/emollick/status/1360763996484366336
Jul 11, 2024
1
(1) Morgan McGuire (Hiring 👋) on X: "RIP RAG “I think long context is definitely the future rather than RAG” On domain specialisation: “If you want a model for medical domain, legal domain…it (finetuning) definitely makes sense…finetuning can also be an alternative to RAG” Great episode, had to listen 0.75x 😂" / X
x.com/morgymcg/status/1810973158331072630
Jul 10, 2024
1
(1) Ethan Mollick on X: "We know good management is causal in part because, a decade ago, teams of consultants introduced basic management practices to some Indian plants & left others as a control. The practices boosted performance then. A followup shows about half the effects persist 10 years later! https://t.co/x4NROBczIJ" / X
x.com/emollick/status/1808922231302422840
Jul 4, 2024
1
(1) Lingming Zhang on X: "Introducing OpenAutoCoder-Agentless😺: A simple agentless solution solves 27.3% GitHub issues on SWE-bench Lite with ~$0.34 each, outperforming all open-source AI SW agents! It's fully open-source, try it out: 🧑💻https://t.co/AKyiZhmi7B 📝https://t.co/Oc4QCaQult https://t.co/gQDfCrLzs3" / X
x.com/LingmingZhang/status/1808501612056629569
Jul 4, 2024
1
Rohan Paul on X: "Quite an wild idea in this paper - Proposes a persona-driven data synthesis methodology using Persona Hub, a collection of 1 billion diverse personas, to create scalable and diverse synthetic data for LLM training and evaluation. 📌 Persona Hub contains 1bn+ personas derived https://t.co/r3pjDYa49u" / X
x.com/rohanpaul_ai/status/1808096574997770590
Jul 3, 2024
1
Pat Walls on X: "Free business idea for anyone that can code: Build a tiny saas around a SINGLE Zapier integration. Hear me out... So Zapier has 6,000 integrations. 6,000! 1. Find an integration that's (1) popular and (2) limited in functionality 2. Make it 10x better, cover edge cases, etc. https://t.co/TppPkhRDNf" / X
x.com/thepatwalls/status/1808150786804707755
Jul 3, 2024
1

AGI will drastically increase economies of scale — LessWrong
www.lesswrong.com/posts/Sn5NiiD5WBi4dLzaB/agi-will-drastically-increase-economies-of-scale
Jul 3, 2024
1
(3) Aidan McLau on X: "livebench (https://t.co/3fKC4vaoTE) is my new favorite eval: > contamination proof (new questions monthly) >tests model iq (unlike arena nowadays) >matches my intuition on relative perf quite well thanks @jpohhhh for the pointer https://t.co/fDXfG51wJe" / X
x.com/aidan_mclau/status/1807875944088326271
Jul 2, 2024
1
(1) Rohan Paul on X: "Brilliant new paper, HUGE for LLM's internalized knowledge 🔥 Out Of Context Learning > In Context Learning | Fine-tuning can teach new concepts better than ICL 📌 Finds a surprising capability of LLMs through a process called inductive out-of-context reasoning (OOCR). In the https://t.co/Ys5LUgLNKp" / X
x.com/rohanpaul_ai/status/1807774433550950816
Jul 1, 2024
1
(1) elvis on X: "This is one of the coolest ideas for scaling synthetic data that I've come across. Proposes 1 billion diverse personas to facilitate the creation of diverse synthetic data for different scenarios. It's easy to generate synthetic data but hard to scale up its diversity which is https://t.co/UR998d49hE" / X
x.com/omarsar0/status/1807827401122238628
Jul 1, 2024
1
Jeff Morris Jr. on X: "“How to ship fast as a small company looking for product-market fit” — by @varunsrin @farcaster_xyz is one of the fastest engineering teams I’ve ever seen… Here is how they operate: https://t.co/AARMozy2zy" / X
x.com/jmj/status/1806125131024183452
Jun 28, 2024
1
Steve Stewart-Williams on X: "The Big 5 personality traits strongly predict life satisfaction (r = .8 - one of the largest effects I’ve seen in a psychology paper). https://t.co/K2OaLCSD0L https://t.co/TlZiLN3ibe" / X
x.com/SteveStuWill/status/1806087660139946432
Jun 28, 2024
1
Greg Kamradt on X: "How do SOTA LLMs do on ARC Prize? We wanted to see how gpt-4o, claude sonnet, and gemini did on public tasks So we made a baseline template with @LangChainAI that tests them all Scores: * Claude Sonnet: 21% * gpt-4o: 9% * gemini 1.5: 8% https://t.co/6wXW8E3vOE" / X
x.com/GregKamradt/status/1806373849333653975
Jun 28, 2024
1
Ethan Mollick on X: "Two big lessons in the new OpenAI paper on training AI to detect AI bugs, 1) Cyborgs rule: AI detected more bugs than humans alone, but humans & AI working together had lower hallucination rates… 2)…for now: human error rates were also high. And read the highlighted conclusion. https://t.co/FbPTQVNPeI" / X
x.com/emollick/status/1806401500194672742
Jun 28, 2024
1
(1) BioBootloader on X: "1/ Thrilled to announce that our team has created the most advanced coding AI in the world, smashing the previous State-of-the-Art by solving 38.33% of SWE-bench Lite! MentatBot is not only the most accurate, but runs extremely quickly and is available for you to use today! https://t.co/FNJ7nPKaNi" / X
x.com/bio_bootloader/status/1806342922893394290
Jun 27, 2024
1

Finding GPT-4’s mistakes with GPT-4
openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
Jun 27, 2024
1
(1) Greg Kamradt on X: "Last week @RyanPGreenblatt shared his gpt-4o based attempt on ARC-AGI We verified his score, excited to say his method got 42% on public tasks We’re publishing a secondary leaderboard to measure attempts like these So of course we tested gpt-4, claude sonnet, and gemini https://t.co/lyfIKNOioL" / X
x.com/GregKamradt/status/1806372523170533457
Jun 27, 2024
1
MultiOn on X: "Introducing Retrieve API: the best-in-class autonomous web information retrieval API. Developers love our Agent API ❤️. Since its launch, we have consistently received feedback that many use cases rely on intelligently leveraging the Agent API to retrieve information from the https://t.co/upOn8TflUj" / X
x.com/MultiOn_AI/status/1806007797030834521
Jun 27, 2024
1
University to Replace Students With ChatGPT After It Outperforms Them in Exams / X
x.com/i/trending/1806333778765271252
Jun 27, 2024
1
Ethan Mollick on X: "This isn't reliable enough yet, but it is a sign of what is coming: Claude 3.5 here's excel of my startup's finances, make a dashboard Add sensitivity analysis of key assumptions Run it as a Monte Carlo simulation Assuming a normal distribution, what are outcomes? All first try https://t.co/JBnudGihja" / X
x.com/emollick/status/1806321738734600337
Jun 27, 2024
1
Marzena Karpinska on X: "Can #LLMs truly reason over loooong context? 🤔 NoCha asks LLMs to verify claims about *NEW* fictional books 🪄 📚 ⛔ LLMs that solve needle-in-the-haystack (~100%) struggle on NoCha! ⛔ None of 11 tested LLMs reach human performance → 97%. The best, #GPT-4o, gets only 55.8%. https://t.co/beuo7q9KIj" / X
x.com/mar_kar_/status/1805660949023793224
Jun 26, 2024
1
Gizem Akdag on X: "Here is a Midjourney Style Reference that I think you'll like: --sref 3721090848. Save this code for calm, soft vibes. This one works really well with architecture, city, and interior design shots. Also, with a 35 mm film look, it gives a vintage feel. This time, I used Krea https://t.co/hKQhkCx6MI" / X
x.com/gizakdag/status/1785257036151656918
Jun 26, 2024
1
Tuhin Chakrabarty on X: "New paper with students @BarnardCollege on testing orthogonal thinking / abstract reasoning capabilities of Large Language Models using the fascinating yet frustratingly difficult @nytimes Connections game. #NLProc #LLMs #GPT4o #Claude3opus 🧵(1/n) https://t.co/jDfCbpPi2Z" / X
x.com/TuhinChakr/status/1805999559585227002
Jun 26, 2024
2
François Fleuret on X: "This is an argument often used (by me included), but I find it slightly unsatisfactory. Consider natural selection as a process that given *tons of training data* produce a 100k x 100k configuration of the game of life (that's roughly the information in human dna). 1/3" / X
x.com/francoisfleuret/status/1806037891757293626
Jun 26, 2024
1
clem 🤗 on X: "Pumped to announce the brand new open LLM leaderboard. We burned 300 H100 to re-run new evaluations like MMLU-pro for all major open LLMs! Some learning: - Qwen 72B is the king and Chinese open models are dominating overall - Previous evaluations have become too easy for recent" / X
x.com/ClementDelangue/status/1805989925080219927
Jun 26, 2024
1
Anna Mills, annamillsoer.bsky.social, she/her on X: "Can we tell when a student submission is AI? This study from the University of Reading suggests not. "The university’s markers – who were not told about the project – flagged only one of the 33 entries." https://t.co/dTuSCTJnHF" / X
x.com/AnnaRMills/status/1806033830027182423
Jun 26, 2024
1
Ethan Mollick on X: "Researchers secretly added AI-created the papers to the exam pool: “We found that 94% of our AI submissions were undetected. The grades awarded to our AI submissions were on average half a grade boundary higher than that achieved by real students.“ https://t.co/z8IX14133B. https://t.co/JDmET3q7pw" / X
x.com/emollick/status/1806040241104470228
Jun 26, 2024
1
(1) https://arxiv.org/abs/2406.13121 - Search / X
x.com/search?q=https%3A%2F%2Farxiv.org%2Fabs%2F2406.13121&src=typed_query&f=top
Jun 26, 2024
1
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
arxiv.org/abs/2406.13121
Jun 26, 2024
1
(2) Posts liked by mark erdmann (@markerdmann) / X
x.com/markerdmann/likes
Jun 25, 2024
2
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
arxiv.org/abs/2406.11695
Jun 25, 2024
1
(1) Dan Hendrycks on X: "Nat's right so I think I'm going to make 2-3 more benchmarks to replace MMLU and MATH." / X
x.com/DanHendrycks/status/1804929811703591345
Jun 24, 2024
1
(2) Eugene Yan (SF 22 - 28 June) on X: "i previously spoke to a team who only used embedding-based retrieval. i suggested, insisted, they try lexical search. at our next chat, they shared that 80% of the relevant docs now come from lexical search. i.e., without lexical search they were missing 80% of the juice for RAG. https://t.co/2N92Xygw1G" / X
x.com/eugeneyan/status/1804270554033328359
Jun 21, 2024
1
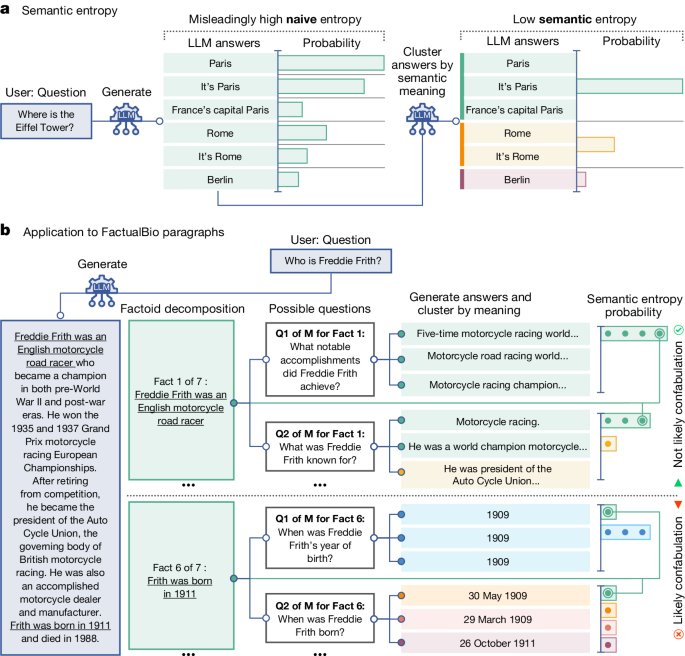
Detecting hallucinations in large language models using semantic entropy - Nature
www.nature.com/articles/s41586-024-07421-0
Jun 21, 2024
1
(2) Andrej Karpathy on X: "The way to think about asking a factual question to an LLM is that it's a bit like asking a person who read about the topic previously, but they are not allowed to reference any material and have to answer just from memory. LLMs are a lot better at memorizing than humans, but the" / X
x.com/karpathy/status/1804208334033371213
Jun 21, 2024
1
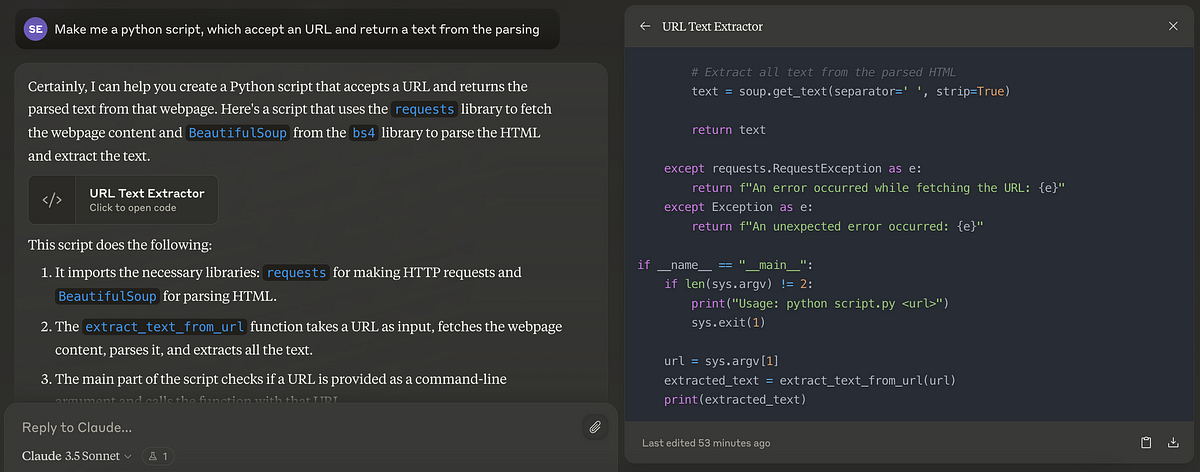
How to use Claude’s artifacts
medium.com/@simeon.emanuilov/how-to-use-claudes-artifacts-908835dbd96a
Jun 21, 2024
1
(1) Keyon Vafa on X: "New paper: How can you tell if a transformer has the right world model? We trained a transformer to predict directions for NYC taxi rides. The model was good. It could find shortest paths between new points But had it built a map of NYC? We reconstructed its map and found this: https://t.co/5z6sglnRIQ" / X
x.com/keyonV/status/1803838591371555252
Jun 20, 2024
2
2406.04692v1.pdf
arxiv.org/pdf/2406.04692
Jun 20, 2024
1

Aqua Voice - Voice-only Document Editor
withaqua.com/?ref=upstract.com
Jun 20, 2024
1
(1) Rob Wiblin on X: ""The results were otherworldly. Claude is fully capable of acting as a Supreme Court Justice right now. When used as a law clerk, Claude is easily as insightful and accurate as human clerks, while towering over humans in efficiency." https://t.co/tfdYtHSqnT https://t.co/83t85g5Wtp" / X
x.com/robertwiblin/status/1803388400084381787
Jun 20, 2024
1

NeurIPS-2021-attention-approximates-sparse-distributed-memory-Paper.pdf
proceedings.neurips.cc/paper_files/paper/2021/file/8171ac2c5544a5cb54ac0f38bf477af4-Paper.pdf
Jun 19, 2024
1
Lienid on X: "@mikeknoop been clear for a while that transformers have nailed associative memory. it even maps to a biologically plausible mechanism. frankly i’m not sure how people haven’t come to this conclusion yet https://t.co/remVwHBlYd" / X
x.com/0xLienid/status/1803530958207066114
Jun 19, 2024
1